高并发的哲学原理(二)-- Apache 的性能瓶颈与 Nginx 的性能优势
《高并发的哲学原理 Philosophical Principles of High Concurrency》开源图书已经发布,简称 PPHC。地址:https://github.com/johnlui/PPHC
每一名后端开发可能都知道 Nginx 比 Apache 性能强,但是为什么强,强在哪里,接下来我们动手实验解答这个问题。
Nginx 利用了新的 Linux kernel API
Nginx 利用了 Linux 内核引入的 epoll 事件驱动 API,大幅降低了海量 TCP 连接下的 CPU 负载,提升了单个系统的 TCP 响应容量,这是 Nginx 性能更好的本质原因:时代在进步。
每一篇技术文章都会说,Nginx 的 epoll 比 Apache 的 select 性能高,但为什么,却几乎没人解释。下面我来尝试解释。
epoll 简单解释
众所周知,epoll 是一种高性能事件驱动 IO 多路复用机制,那他和 select 这种原始 IO 多路复用机制比有什么优势呢?简单来说,就是:转守为攻。
epoll 化被动为主动,以前需要两次遍历才能实现的网络数据包和线程的匹配,现在通过事件驱动的方式主动献上指针,性能暴增。这就像云原生时代的 Prometheus 监控:化主动上传为被动查询,大幅提升单个采集节点的性能上限,成功解决了监控领域的高并发性能问题。
在 5K 个 TCP 连接的情况下,每收到一个数据包,Nginx 找到对应线程的速度比 Apache 高了两个数量级,即便是 event 模式下的 Apache,性能依然远低于 Nginx,因为 Nginx 就是专门为“反向代理”设计的,而 Apache 本质是个 web 应用容器,无法做到纯粹的事件驱动,性能自然无法和 Nginx 相比。
Apache 的原始并发模型
Apache 支持三种进程模型:prefork、worker 和 event,在此我们简单讨论一下这三种模式的优缺点。
-
prefork 是进程模式,需要消耗更多的内存,每次接到一段新的数据,需要使用
select模型,遍历TCP连接数 x 进程数这么多次才能找到匹配的进程,在数千个 TCP 连接下,光是寻找线程就需要消耗掉一个 CPU 核心,单机性能达到极限,无法利用更多的 CPU 资源 -
worker 是线程模式,依旧使用
select模型来遍历 TCP 请求和线程,性能上限和 prefork 一致,区别是内存消耗量有了一些降低,初始 TCP 承载能力稍好,请求数突然增加的场景下,开新线程的速度反而比 prefork 更慢,且基础延迟比 prefork 模式更高 -
event 模式采用和 Nginx 一致的
epoll模型承载,理论上表现和 Nginx 一致,但由于 Apache 大概率和 mod_php(插件)模式的 PHP 一起部署,由于 PHP 阻塞运行的特性,性能和上面两兄弟并无明显区别。而且即便是 event 模式下的 Apache,性能依然远低于 Nginx。
接下来我们使用 jmeter 测试一下 prefork、worker、event 三种模式的性能。
压力测试
测试环境
-
客户端:
- i5-10400 6 核 12 线程
- 32GB 内存
- 千兆有线网络
-
软件环境
- macOS
- Java 19.0.1
-
服务端:
- 物理服务器 E5-2682V4 2.5GHz 16 核 32 线程 * 2 (阿里云 5 代 ECS 同款 CPU)256GB RAM
- 虚拟机 64 vCPU (赋予了虚拟机所有母鸡的 CPU 资源)
- 虚拟机内存 32GB
-
软件环境
- CentOS Stream release 9
- kernel 5.14.0-200.el9.x86_64
- Apache/2.4.53
- Nginx/1.20.1
- PHP 8.0.26
-
PHP 环境:
- Laravel 9.19
- 给默认路由增加 sleep 500ms 的代码,模拟数据库、Redis、RPC、cURL微服务等场景
-
执行
php artisan optimize后测试
-
测试代码
Route::get('/', function () { usleep(500000); return view('welcome'); });
-
Apache prefork 模式配置
StartServers 100 MinSpareServers 5 MaxSpareServers 100 MaxRequestWorkers 500 MaxRequestsPerChild 100000 -
php-fpm 配置
pm = static pm.max_children = 500
试验设计
我们将测试三种配置下的性能表现差异:
- Apache 标准模式:prefork + mod_php 插件式运行 PHP
- Nginx + php-fpm 专用解释器
- Nginx 作为 HTTP 反向代理服务器后接 Apache(prefork 模式 + mod_php 插件式运行 PHP)
请求计划
- 客户端新线程开启后,每隔 5 秒发送一个请求
- jmeter 用 50 秒开 5000 个线程,持续压测 100 秒,最大请求 QPS 为 1000
为什么这么设计?
单独对比 Nginx 和 Apache 性能的文章很多,数据结果也大同小异,无非是 Nginx 的 QPS 更高,但是为什么却没人回答,我本次的实验设计就是要回答这个问题。
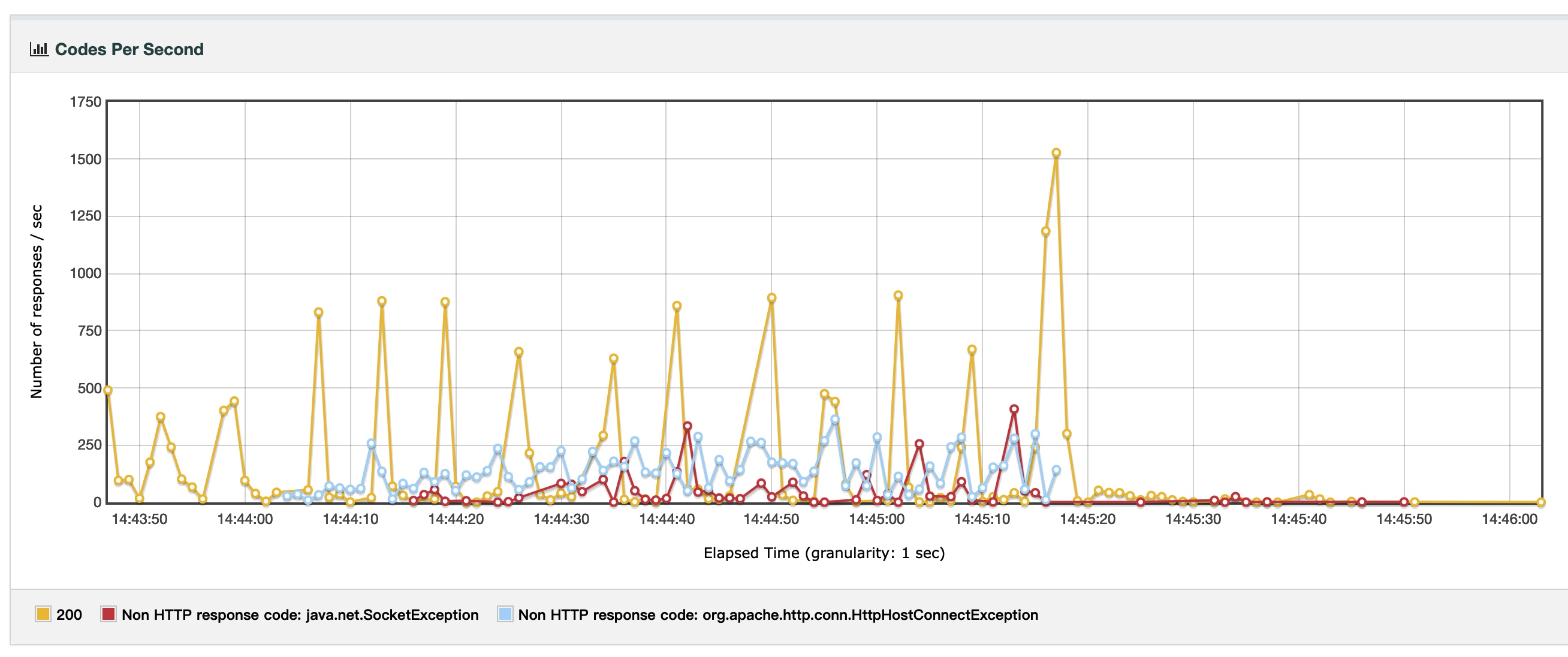
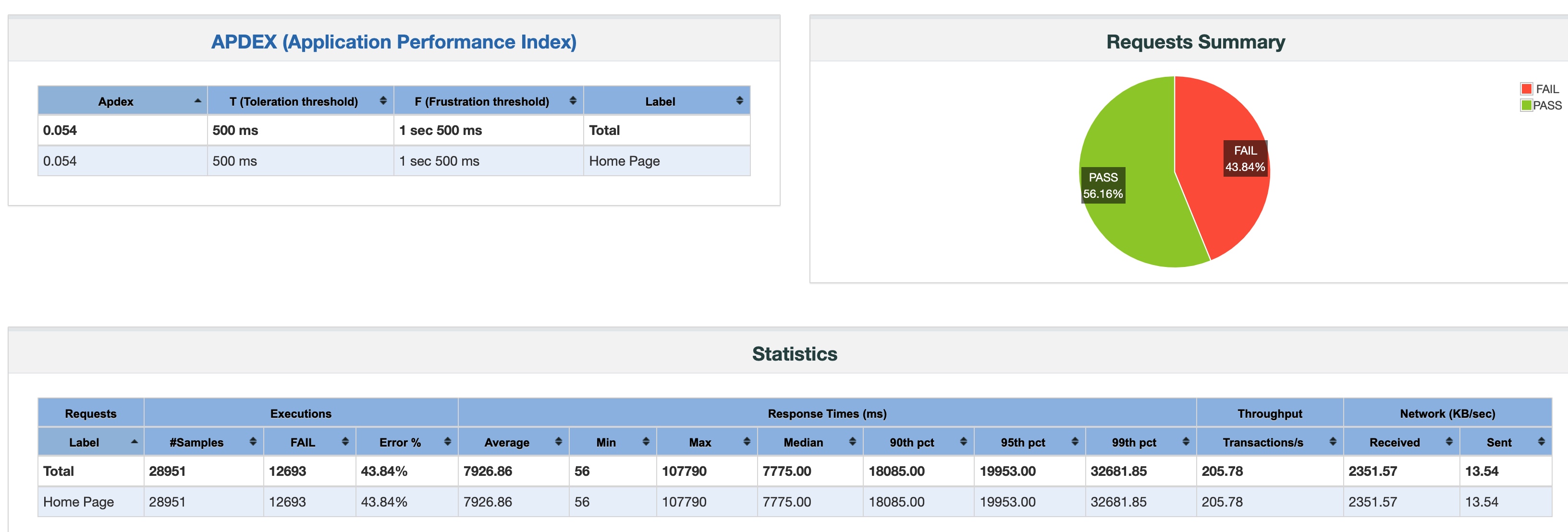
Apache 标准模式:prefork + mod_php
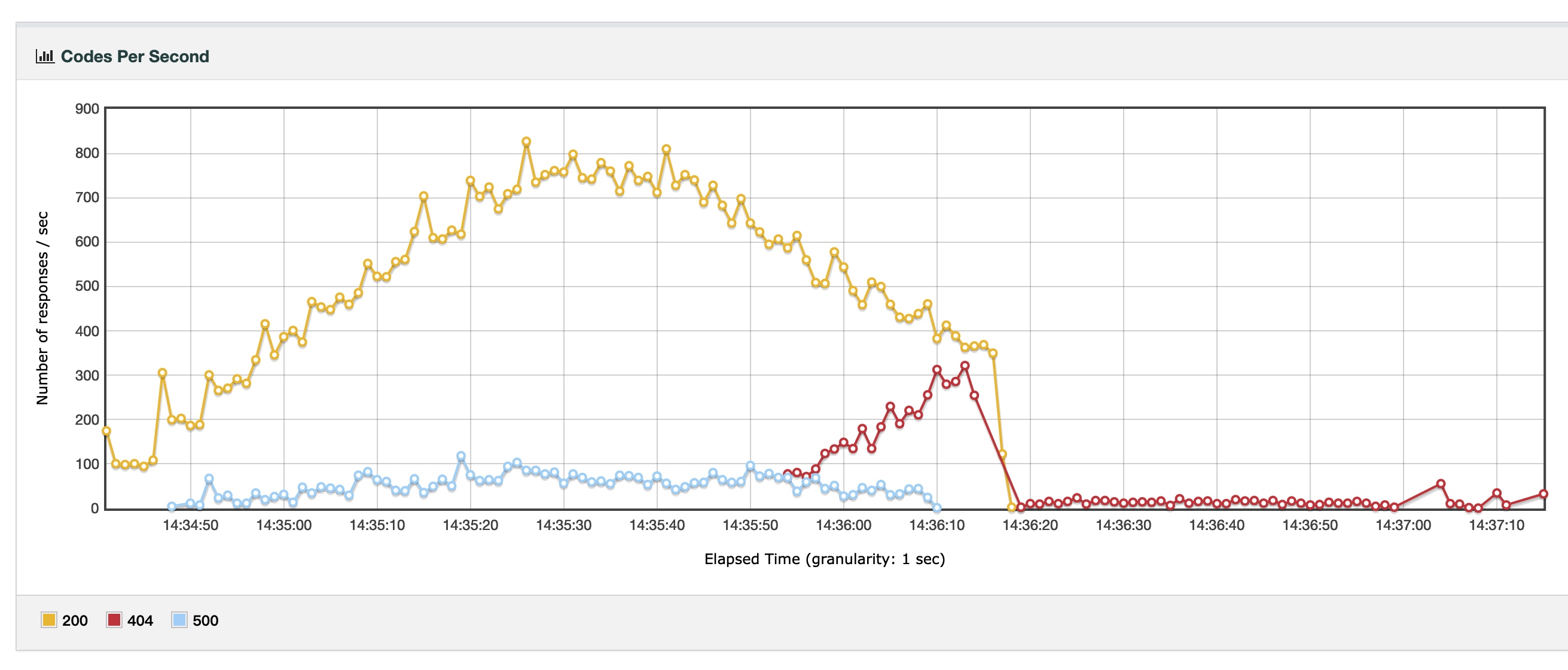
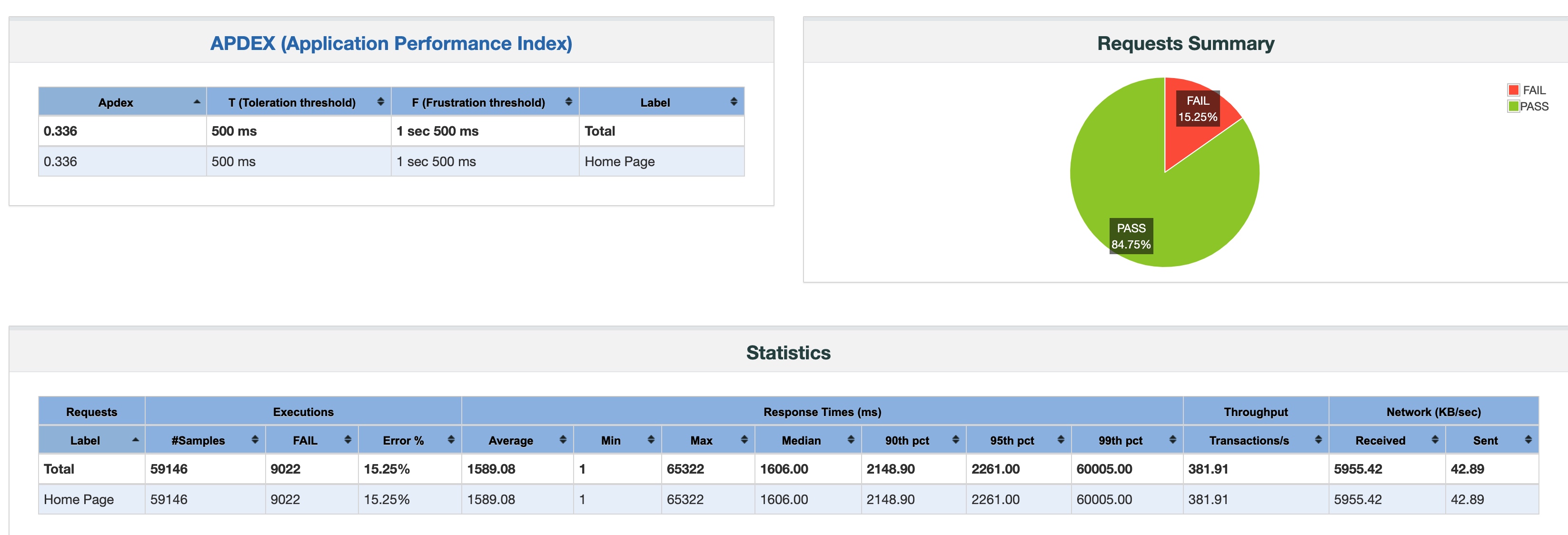
nginx + php-fpm
nginx 反向代理 Apache 标准模式
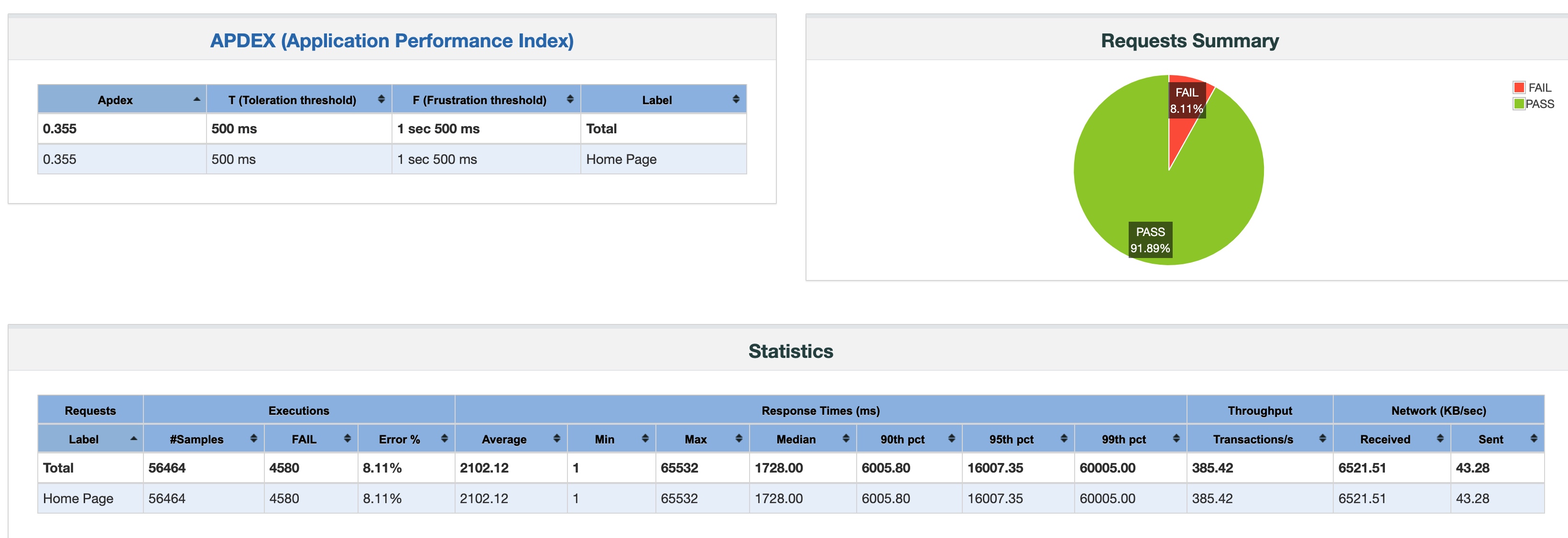
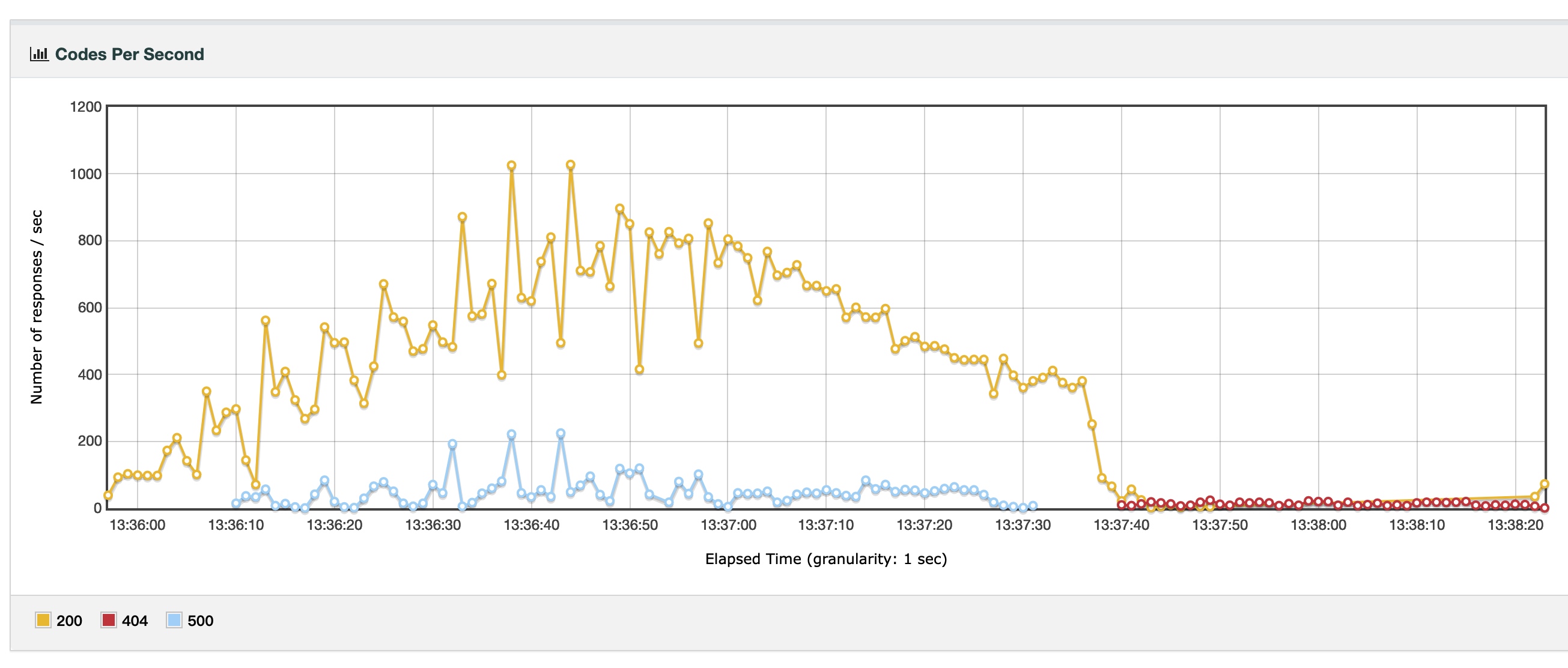
结果分析
我们可以很明显地看出,Apache + prefork 的问题在于它对数千个 TCP 连接的处理能力不足。
- Nginx + fpm 一共发出了 59146 个请求,成功了五万个
- Nginx + Apache 一共发出了 56464 个请求,成功了五万两千个,比 fpm 还多一些
- fpm 模式最大 QPS 为 800 但比较稳定,Nginx + Apache 最大 QPS 1000 但不够稳定
- 至于 Apache 标准模式,显然它的技术架构不足以处理 5000 个 TCP 连接下 1000 QPS 的状况,QPS 低且不稳定,错误率高达 43%
结论:
- Nginx 处理海量用户的海量 TCP 连接的能力超群
- 提升 Apache 性能只需要在前面加一个 Nginx 作为 HTTP 反向代理即可,因为此时 Apache 只需要处理好和 Nginx 之间的少量 TCP 连接,性能损耗较小
- php-fpm 和 mod_php 在执行 PHP 的时候没有任何性能差异
Nginx epoll 和 Apache prefork 模型相比,优势劣势如下:
优势
- Nginx 每个 worker 进程可以 handle 上千个 TCP 连接,消耗很少的内存和 CPU 资源,可以让单台服务器承接比 Apache 多两个数量级的用户量,相比于 Apache 单机 5K 的 TCP 连接数上限(对应的是 2000 个在线用户),是一个巨大的进步
- Nginx 对 TCP 的复用使它非常善于应对海量客户端的直接连接,根据我的实测,在 HTTP 高并发下 Nginx 的活跃 TCP 连接数可以做到 Apache 的五分之一,而且用户量越高,复用效果越好
- 在架构上,基于 FastCGI 网络协议进行架构扩展,也可以更轻易地利用多台物理服务器的并行计算能力,提升整个系统的性能上限
劣势
- 在低负载下,Nginx 事件驱动的特性使得每个请求的响应时长比 Apache prefork 模式略长一些(14ms vs 9ms)
我的真实经验
新冠时期的爱情机遇
疫情初期,我司的私域电商业务兴起于草莽之间,在 3 月中旬才上班的情况下,半个月的 GMV 超过了前面一年,4 月就完成了全年目标,电商系统性能压力陡增。
当时我们的电商系统是购买的一个 PHP 单体系统,天生不具有扩展性,外加业务模式是团购秒杀,可要了亲命了。客户端为微信小程序,服务端主要提供两种业务:开团瞬间的海量 HTTP API 请求,以及每一个页面都非常消耗资源的订单管理后台。
当时我面临的第一个问题是数据库顶不住,我找到请求数最高的接口:商品详情,为它增加了一层保持时长为一分钟的 Redis 缓存,开团瞬间数据库的压力降低了很多。
而且幸运的是当时阿里云刚刚将 PolarDB 商用几个月,我用它顶住了开团三分钟内涌入的大约 4000 名用户,但是当我把虚拟机升级到 16 核 32G 内存的时候出现了一个非常诡异的现象:
- CPU 和内存占用率分别只有 8% 和 6%
- 但大量的新用户就是无法建立 TCP 连接,首次连接的客户端表现为长时间的等待
- 如果运气好在等待一段时间后成功进去了,那访问便会一直如丝般顺滑,每个接口的返回时间都非常短
这是为什么呢?这是因为新用户无法和服务器建立 TCP 连接!
默认情况下,CentOS 7.9 的最大文件打开数(ulimit)为 1024,一切皆文件,每个 TCP 连接也是一个文件,所以也被锁定在了 1024 个。一般大家都会把这个数字设置为 65535,但是我观察到,这台虚拟机此时的 TCP 连接数只能跑到 5-6K 之间,远远达不到用户的需求,无论是采用 prefork、worker 还是 event 都是这样。而原因就是我们上面实测过的:此时 Apache 花费了一颗核心的全部时间片来进行数据包和线程的匹配,已经忙不过来了。
后来,我在这台机器上安装了一个 Nginx,反向代理全部的用户请求再发送给 Apache:请求一下子舒畅了,而且 Nginx 使用的最大活跃 TCP 连接数量也只有 1K,就完全满足了三分钟 4000 用户的需求。
还记得我们的目标吗?一百万 QPS
在 2022 年的主流云服务器硬件上,经过 OPCache 性能优化的 PHP 应用,只需要 2 vCore 便可以达到 5K 的单机 Apache TCP 上限,此时 QPS 在 200 左右,单纯提升核心数量无法让这个数字大幅增加。而通过使用 Nginx,我们可以将单系统的 QPS 上限从 200 提升到 1000。
接下来
下一篇文章,我们将讨论基础设施层面的并发:虚拟机和 k8s 技术。同时我会继续现身说法,讲述我为自研团购秒杀系统设计的架构,我称它为百亿架构(年 GMV 百亿之前不用换架构)。


评论:




2023-05-25 09:42
看了您这个文章我想用大白话描述一下select和epoll 的区别,麻烦您给我看下我是否描述错误
select:
类似于每次使用for循环遍历元素,可以认为如果for循环中有一个元素(不会重复)匹配上了。就会去调用那个元素的具体方法,缺点是每次都要循环变量,这样在元素很多的情况下,肯定会对性能有影响
epoll:
类似于Dubbo官网介绍的consumer(client)和provider(server)的调用关系
第一次consumer首先从注册中心获取到provider的地址 -> consumer调用provider
第二次consumer不经过注册中心(可以理解为client与server已经做了映射关系) -> consumer直接调用provider