高并发的哲学原理(五)-- 拆分网络单点(上):应用网关、负载均衡和路由器(网关)
《高并发的哲学原理 Philosophical Principles of High Concurrency》开源图书已经发布,简称 PPHC。地址:https://github.com/johnlui/PPHC
上一篇文章的末尾,我们提到了一个假想出来的五万 QPS 的系统,以及这种规模的系统架构中必然存在的负载均衡器,那本篇文章我们就来一起利用负载均衡搭建一个能够支撑五万 QPS 的系统。
“监听 HTTPS 443 端口的进程”这个单点
之前,我们拆出了“监听 HTTPS 443 端口的进程”这个单点,并用 kong 网关来承载了这个单点。目前,在 2 vCore 的虚拟机上,2000 QPS 的压力对应的大约是 20% 的 CPU 占用率,经过换算我们可以知道:假如 kong 的性能可以随着核心数增加而线性提升的话,在维持最大 40% CPU 占用率的情况下,需要:
(50000 / 2000) 2 (20% / 40%) = 25 核
在这里我们先假设我们搞了一个 25 核的虚拟机,接住了这五万 QPS(实际上接不住,我们后面会说),那这个 Kong 网关到底是什么玩意儿呢?它就是标题中的“应用网关”。
应用网关
应用网关,又称 API 网关,顾名思义,它就是所有 API 请求的大门:自己接下所有的 HTTP/HTTPS/TCP 请求,再将请求转发给真正的上游服务器。而这些上游服务器可能是一堆虚拟机,也可能是一堆容器,甚至可以是多个数据中心各自的应用网关。由于应用网关做的事情非常少,所以它能支撑很高 QPS 的系统。
常见的应用网关软件有 HAProxy、Nginx、Envoy 等,而 Cisco、Juniper、F5 等一体化设备厂商也有相关的硬件产品。
应用网关除了提升系统容量外,还有很多别的优势。
1. 解放后端架构
经过对应用网关两年的使用,我现在认为所有系统都应该放在应用网关的背后,包括开发环境。
应用网关对后端架构的解放作用实在是太大了,可以让你在后端玩出花来:各种语言、各种技术、各种部署形式、甚至全国各地的机房都可以成为某条 URL 的最终真实服务方,让你的后端架构彻底起飞。
2. TLS 卸载
终端用户访问应用网关的时候采用的是 HTTPS 协议,这个协议是需要对数据进行加密解密的,应用网关非常适合干这件事情,而背后的业务系统只提供标准 HTTP 协议即可,降低了业务系统的部署复杂度和资源消耗。
3. 身份验证和安全性提升
应用网关可以对后端异构系统进行统一的身份验证,无需一个一个单独实现。也可以统一防火墙白名单,后端系统防火墙只对网关 ip 开放,极大提升了后端系统的安全性,降低了海量服务器安全管理的难度。甚至可以针对某条 API 进行单独鉴权,让系统的安全管控能力大幅提升。
4. 指标和数据收集
由于所有流量都会经过网关,所以对指标进行收集也变的简单了,你甚至可以将双向流量的内容全部记录下来,用于数据统计和安全分析。
5. 数据压缩与转换
应用网关还可以统一对流量进行 gzip 压缩,可以将所有业务一次性升级到 HTTP/2 和 HTTP/3,可以对数据进行格式转换(XML 到 JSON)和修改(增加/修改/删除字段),总是就是能各种上下其手,翻云覆雨,随心所欲。
负载均衡
应用网关的另一个价值就是负载均衡了:可以将请求的流量按照各种比例分发给不同的后端服务器,提升系统容量;可以做红蓝发布和金丝雀发布;可以针对流量特点做灰度发布;可以主动调节各个后端服务器的压力;屏蔽失效的后端服务器等等。
低负载下应用网关和负载均衡可以是同一个软件
虽然应用网关和负载均衡是两个不同的概念,但在低负载系统里,他们两个往往由同一个软件来扮演,例如前面说到的 Kong 网关就同时具备这两个功能。
拆分应用网关
一个五万 QPS 的系统,是无法使用 25 核的单机安装 Kong 网关来承载的,因为此时单机 TCP 连接数已经达到了十万以上,在这个条件下强如 Nginx 也达到性能极限了,性能不再增长甚至会开始下降,用户体验也会迅速变差。此时,我们需要对应用网关进行拆分。
应用网关怎么拆
逻辑上,应用网关执行的是“反向代理+数据过滤”任务,并没有要求应用网关只能由一台服务器来承接,换句话说,应用网关不是单点,只要多个节点的行为一致,那就可以共同承接这五万 QPS 的真实用户流量。
我们只需要在多台机器上装上同样版本的应用网关软件,然后在他们之间同步配置文件即可。Kong 采用的策略是让多个实例连接同一个PostgreSQL数据库,每五秒从数据库获取一次最新的配置,如果数据库挂掉,那就保持内存中的现有配置继续运行。
Kong 集群追求的是“最终一致性”,不追求五秒的得失,反而让系统格外地容易扩展,格外的健壮,最后一篇文章我们还会见到使用类似思维的“DNS 分布式拆分”。这个朴素的分布式架构颇有毛子暴力美学的风范,后面我们讨论列存储 clickhouse 的时候还能见到。
如果单个应用网关扛不住五万 QPS,那我们搞一个负载均衡器放在应用网关的前面,架构图如下:
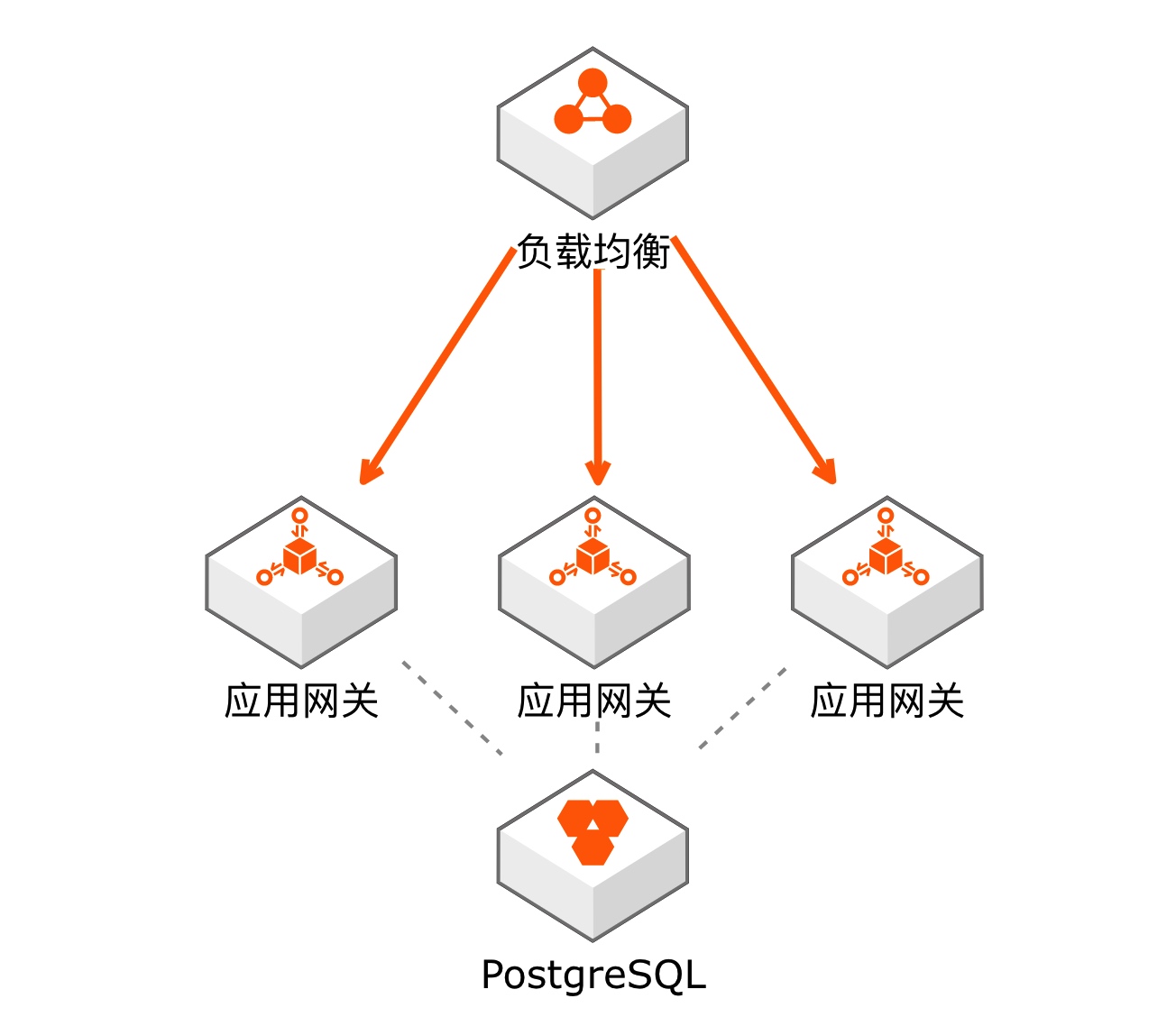
分层的网络
负载均衡器为何能抗住五万 QPS
看到这里有人可能会疑惑,既然单机的 Nginx 都顶不住五万 QPS 带来的 TCP 资源开销,那负载均衡器如何抗住呢?因为负载均衡器承载的是比 Nginx 所承载的 TCP 更下面一层的协议:IP 协议。
至此,我们正式进入了网络拆分之路,这条路很难走,但收益也会很大,最终我们将得到一个 200Gbps 带宽的软件定义负载均衡集群,让我们正式开始。
网络是分层的
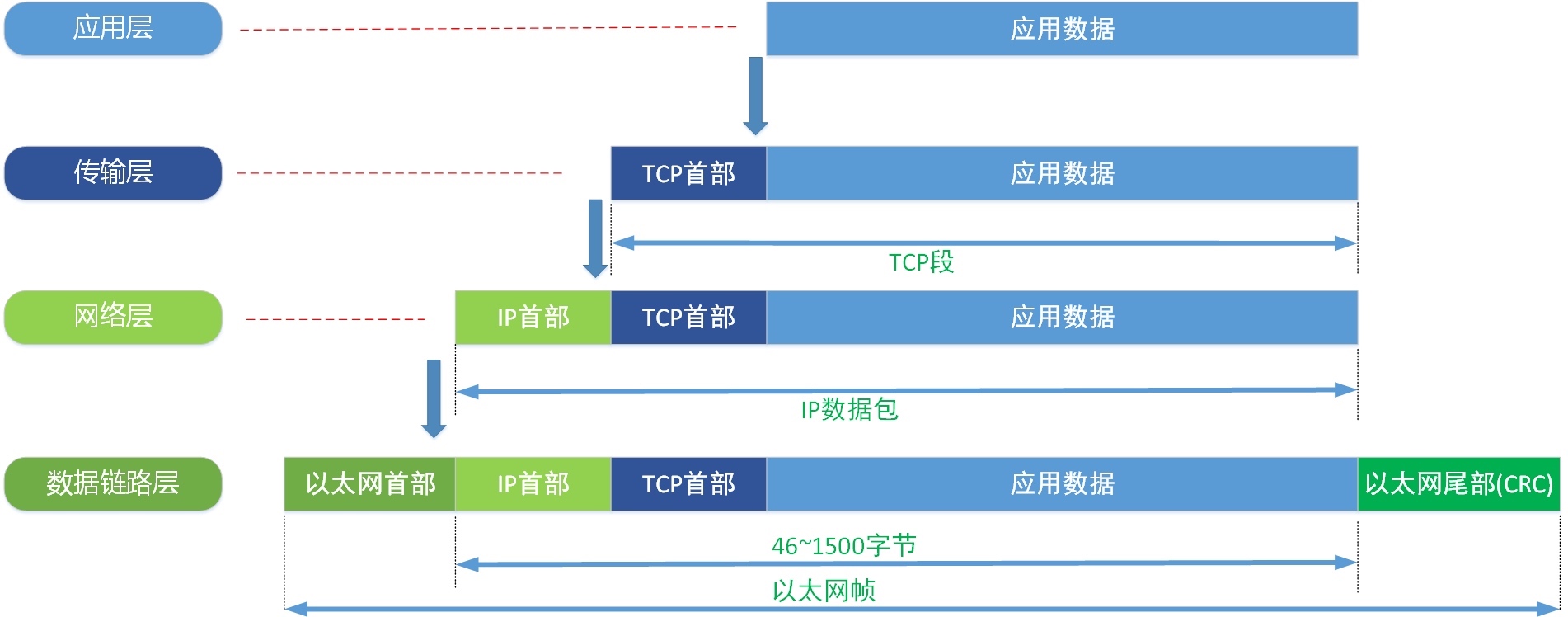
上面这张图引用自我的另一个系列文章:软件工程师需要了解的网络知识:从铜线到HTTP(三)—— TCP/IP¹。
如果你查看过网页的源代码,你就能知道网页背后是一段 HTML 代码,这段代码是被层层包裹之后,再在网络中传输的,就像上图中一样。以太网之所以拥有如此之强的扩展性和兼容能力,就是因为它的“分层特性”:每一层都有专门的硬件设备来对网络进行扩展,最终组成了这个容纳全球数十亿台网络设备的“互联网”。最近,这些传统硬件设备的工作越来越多地被软件所定义,即软件定义网络(SDN)。
应用数据是什么
应用数据就是网页背后的 HTTP 协议所包含的全部数据。
我们使用 Charles 反向代理软件可以轻易地得到 HTTP 协议的细节。下面我们展示一个普通的 GET 例子。使用浏览器访问 http://httpbin.org (自己尝试的时候不要选择 HTTPS 网站):
请求内容
GET / HTTP/1.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cache-Control: max-age=0
Connection: keep-alive
Host: httpbin.org
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54数据解释:
- 第一行有三个元素:HTTP 方法、uri、HTTP 版本
-
之后的每一行均以冒号
:作为间隔符,左边是 key,右边是 value - HTTP 协议中,换行采用的不是 Linux 系统的 \n,而是跟 Windows 一样的 \r\n
响应内容
HTTP/1.1 200 OK
Date: Wed, 04 Jan 2023 12:07:36 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 9593
Connection: keep-alive
Server: gunicorn/19.9.0
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>httpbin.org</title>
<link href="https://fonts.googleapis.com/css?family=Open+Sans:400,700|Source+Code+Pro:300,600|Titillium+Web:400,600,700"
rel="stylesheet">
<link rel="stylesheet" type="text/css" href="/flasgger_static/swagger-ui.css">
<link rel="icon" type="image/png" href="/static/favicon.ico" sizes="64x64 32x32 16x16" />
</head>
<body>
<a href="https://github.com/requests/httpbin" class="github-corner" aria-label="View source on Github">
</a>
... ... 此处省略一万个字
</div>
</body>
</html>响应数据的基本规则和请求一样,第一行的三个元素分别是 协议版本、状态码、状态码的简短解释。唯一的不同是,返回值里面还有 HTTP body。
HTTP header 和 HTTP body
- 两个换行即 \r\n\r\n 之前的内容为 HTTP header
- 两个换行之后的内容为 HTTP body
- HTTP body 就是你在浏览器“查看源代码”所看到的内容
HTTP 下面是 TCP 层
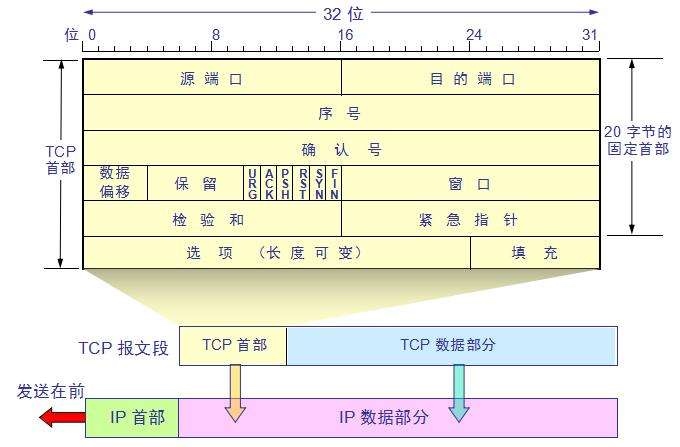
TCP 首部重要数据描述
-
TCP 首部中最重要的数据是
源端口和目的端口 - 他们各由 16 位二进制数组成,2^16 = 65536,所以网络端口的范围是 0-65535
- 我们可以注意到,目的端口号这个重要数据是放在 TCP 首部的,和更下层的 IP 首部、以太网帧首部毫无关系
TCP 下面是 IP 层
全球所有公网 IPv4 组成了一个大型网络,这个 IP 网络其实就是互联网的本体。(IPv6 比较复杂,本文在此不做详细讨论,以下示例均基于 IPv4)
在 IP 层中,每台设备都有一个 ip 地址,形如123.123.123.123:
- IPv4 地址范围为 0.0.0.0 - 255.255.255.255
- 255 为 2 的 8 次方减一,也就是说用八位二进制可以表示 0-255
- 四个八位即为 32 位,4 个字节
IP 首部有哪些信息
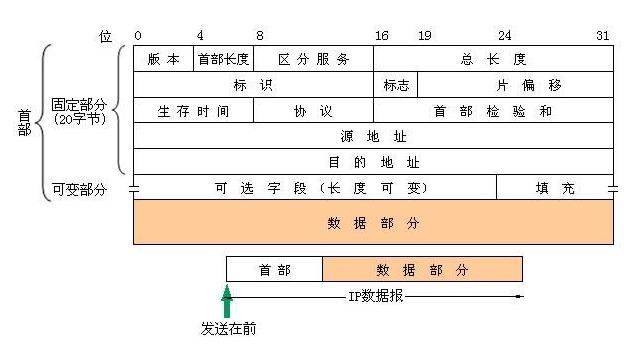
从上图可以看出,ip 首部有 20 字节的固定长度是用来存储这个 IP 数据包的基本信息的:
- 源地址 32 位(4 个字节):123.123.123.123
- 目的地址 32 位(4 个字节):110.242.68.3
- 协议 8 位(1 个字节):内部数据包使用的协议,即 TCP、UDP 或 ICMP(就是 ping 命令使用的协议)
- 首部检验和 16 位(2 个字节):此 IP 首部的数据校验和,用于验证 IP 首部的数据完整性
ip 首部最重要的数据是源 ip 地址和目的 ip 地址
IP 层下面是 MAC 层(物理层)
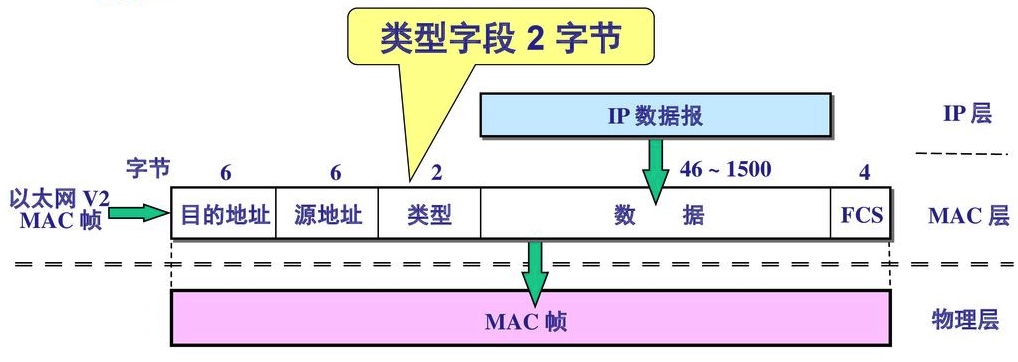
物理层中的二进制数据以上图中的格式进行组织,其基本单元被称为“MAC 帧”。
每一台网络设备的 MAC 帧的长度不一定一致,默认为 1500,即 IP 层的数据会按照这个长度进行分包。在局域网速度跑不到协商速率,需要做性能优化时(例如 iSCSI 网络磁盘),可以使用“巨型帧”技术,将这个数字增加到一万,可以提升网络传输性能。不过,根据我的实际优化经验,绝大多数场景下,巨型帧对网络性能的提升小于 5%,属于一种聊胜于无的优化手段。
目的地址和源地址均为 MAC 地址,形式如 AA:BB:CC:DD:EE:FF,共有六段,每一段是一个两位的 16 进制数,两位 16 进制数换算成二进制就是 8 位,所以 MAC 地址的长度为 8*6 = 48 位。
类型字段采用 16 位二进制表示更上一层(ip 层)的网络层数据包的类型:IPv4、IPv6、ARP、iSCSI、RoCE 等等。
MAC 层就是交换机工作的地方,我们下篇文章会讲。
Nginx 的性能极限
在真实世界中,QPS 一般比保持 TCP 连接的客户端的数量要少,在此我们假设为四分之一,即:有 20 万个客户端设备在这段时间内访问我们的系统,每个客户端设备平均每 4 秒发送一个 HTTPS 请求。
单台 Nginx 反向代理的性能极限
由于 Nginx 不仅需要建立 TCP 连接,还需要将 TCP 连接中发送过来的数据包和某个进程/线程进行匹配,还需要对 HTTP 协议的信息进行解析、识别、转换、添加,所以它也有 QPS 上限:
在 2015 年主流的服务器 CPU 上,Nginx 官方在进行了极限优化的情况下进行了反向代理性能测试,在“建立 TCP 连接-发送 HTTPS 请求-断开 TCP 连接”的极限拉扯下,最高性能为 6W QPS(SSL TPS RSA 2048bit)²。
假设我们使用最新的服务器硬件,当虚拟机 CPU 达到 32 vCore 的时候,未经优化的单机 Nginx 性能就已经达到极限,能承受大约 1 万 HTTPS QPS,对应的连接用户就是 4 万,这个数字其实已经很夸张了。
TCP 负载均衡器为何能抗住五万 QPS
我们假设单台 Kong 应用网关的极限为 1 万 QPS,于是我们就需要五台 Kong,那这五台 Kong 前面的 TCP 负载均衡为何能够抗住呢?因为 TCP 负载均衡器要干的事情比 Kong 少非常多:它只需要在 IP 层做少量的工作即可。
使用负载均衡器拆分 TCP 单点
TCP 协议是一种“可靠地传输信息”的方法,它不仅有三次握手四次挥手等复杂的控制流程,还会对每一个报文段进行排序、确认、重发等操作来保证最终数据的完整和正确,所以,TCP 本身就是一种需要很多资源处理的单点,接下来我们开始拆这个单点。
TCP 负载均衡器的工作过程
我们假设客户端 ip 为 123.123.123.123,负载均衡器的 ip 为 110.242.68.3(公网)和 10.0.0.100(私网),五台 Kong 服务器的 ip 为 10.0.0.1 ~ 10.0.0.5,架构图如下:
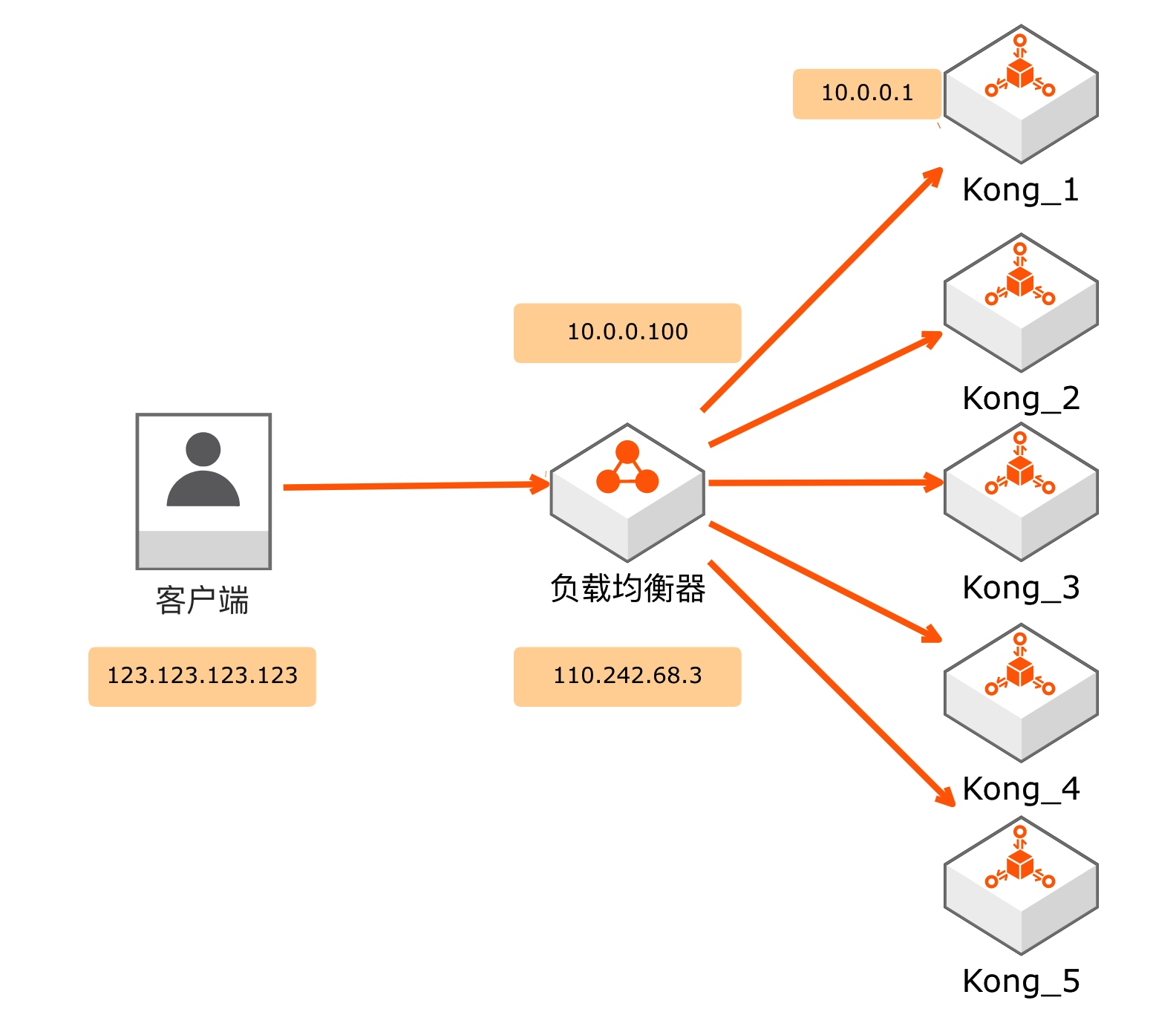
负载均衡器的工作过程如下:
1. 接收数据(左侧)
负载均衡器接收客户端数据包(报文)的过程如下:
- 负载均衡器收到了一个 ip 报文:源地址 123.123.123.123,目的地址 110.242.68.3
- ip 报文内包裹着一个 TCP 报文,详情如下:源端口 52387,目的端口 443
- 注意,负载均衡器只是接收了一个 IP 报文,并没有和客户端进行三次握手,并没有和客户端建立“TCP 连接”
2. 发送数据给上游服务器(右侧)
在接收到客户端的 IP 报文以后,负载均衡器会找一台上游服务器,准备把数据发送过去:
- 内部 TCP 报文首部:源端口 45234,目的端口 443
- TCP 报文外面包裹的 IP 首部:源地址 10.0.0.100,目的地址 10.0.0.1
- 负载均衡器将包裹着 TCP 数据包的 IP 报文发送了出去
3. 建立两个报文的映射关系并进行数据转发
负载均衡器会在内存里创建两个五元组:
左侧五元组
- 左侧源地址 123.123.123.123
- 左侧目的地址 110.242.68.3
- 左侧源端口 52387
- 左侧目的地址 443
- 协议 TCP
右侧五元组
- 右侧源地址 10.0.0.100
- 右侧目的地址 10.0.0.1
- 右侧源端口 45234
- 右侧目的地址 443
- 协议 TCP
然后,负载均衡器会关联这两个五元组:对两侧发来的数据包(报文)进行拆包和修改(两个地址+两个端口),并从另一侧发送出去。
这是什么?这就是你家的路由器(网关)呀
看过我《软件工程师需要了解的网络知识》系列文章的同学应该能一眼看出,这就是网关的工作模式,你家几百块的路由器主要干的就是这个工作。
为什么性能开销比 Kong 低
我们可以看出,负载均衡器/网关只需要做两件事:
- 建立两个五元组并关联
- 修改数据包的地址和端口,再将数据包发送出去
这个操作在网络领域内被称作 NAT(网络地址转换)。
由于这个工作非常简单,其中大部分的工作都可以用专用硬件来解决:例如开发专门的五元组存储和关联芯片,开发专门的 NPU(网络数据包处理器)来进行快速数据修改。所以,家用路由器可以做到在 300 块终端售价的情况下实现超过 1Gbit/S 的 NAT 性能。
Kong 网关需要建立“TCP 连接”
Kong 网关需要真的和客户端“建立 TCP 连接”:
- 三次握手建立连接
- 对数据包进行排序、校验,收到心跳包需要回复
-
需要将这个 TCP 连接和一个进程/线程进行绑定:
- 在收到数据以后,找出这个进程/线程,把数据发送给它
- 等进程/线程回复以后,再找到该进程/线程对应的那个 TCP 连接,把数据发送出去
四层负载均衡(L4)和七层负载均衡(L7)
在卖负载均衡的商业公司那里,应用网关也叫七层负载均衡,因为它工作在 OSI 七层网络模型的第七层,而我们讨论的工作在 IP 层的负载均衡叫四层负载均衡,工作在 OSI 七层网络模型的第四层。再看到 L4 L7 这两个词,你们就能一眼看穿它了,其实一点都不神秘。
还记得我们的目标吗?一百万 QPS
我们通过使用一个负载均衡器,可以完美抗下五万 QPS 的负载:一个 TCP 负载均衡器,下挂五个安装了 Kong 应用网关的虚拟机,再下挂 N 台虚拟机,无论是 PHP 语言还是 golang,都可以实现五万 QPS 的设计目标。
接下来
下一篇文章,我们将着手突破普通 Linux 系统网络性能的上限:使用软件定义网络(SDN)替代百万人民币的负载均衡硬件,并最终搭建出一个能够支撑 200 Gbps 带宽的负载均衡集群。
参考资料
- 软件工程师需要了解的网络知识:从铜线到HTTP(三)—— TCP/IP https://lvwenhan.com/tech-epic/487.html
- 6W QPS(SSL TPS RSA 2048bit) https://www.nginx.com/resources/datasheets/nginx-plus-sizing-guide/


评论:





2023-04-04 10:05