Lower Latency Is All You Need 降低延迟,提升性能!
引子:从一次服务器迁移说起
2022 年,为了顺应降本增效的市场大环境,我决定把一个非关键服务从云上搬迁到本地机房的二手服务器上,节省一些云服务器的费用。这是一个面向搜索引擎 SEO 的 CMS 站点,重度依赖 ElasticSearch,轻度依赖 MySQL 和 Redis,所以我首先把后端应用和 ES 集群搬迁到了本地,MySQL 暂时留在了云上,本地机房的后端代码直接访问云上数据库。
在 Kong 网关的配合下,倒是也实现了服务的无缝切换,0 停机切换完成了。但是,跑起来之后我发现,之前平均 120ms 的页面响应时间大幅增加到了 500ms 以上,页面明显卡顿。经过我一顿代码追踪,发现本地机房的后端代码每次请求云上数据库,延迟都在 10ms 以上,而云上后端代码的延迟在 1ms 以内。而每个 CMS 页面内的 SQL 查询都有几十条,链式放大的延迟累加下来,页面总响应时间就 500ms 了。随后我把数据库也搬到了本地机房,世界美好了。
从这个故事可以看出,延迟是性能的隐形杀手,做性能优化需要系统性思维。目前常见大规模分布式系统一般会采用所谓异地多活的架构来搭建,其实就是按照地理位置分区:给北京的用户 ID 绑定北京机房,哪怕他出差去了上海,也要把他的请求路由回北京机房,千万不能让上海机房的后端代码直接读写北京机房的数据库,延迟会爆炸的。
带宽的突飞猛进
过去十年,我们日常使用的很多技术的“带宽”在数字上实现了非常夸张的进步:
| 2014 年 | 2024 年 | 倍率 | |
|---|---|---|---|
| 北京家庭宽带速率 | 20Mbps 及以下占比 86% | 运营商最低家庭带宽 200M~300M,2023Q1 荣膺世界网速最快城市 | 15 |
| 电脑 PCIe 速率 | 正在普及 PCIe 3.0,X16 约 16GB/S | 正在普及 PCIe 5.0,X16 约 64GB/S | 4 |
| 内存速度 | DDR3 1600MHz 为主流,双通道速率 24GB/S | DDR5 5600Mhz 为主流,双通道速率 98GB/S | 4 |
| 硬盘速度 | 机械硬盘为主流,100MB/S;最先进的 SATA SSD 500MB/S | PCIe 4.0 SSD 为主流,7000MB/S;最先进的 PCIe 5.0 NVME 14000MB/S | 70 |
| WiFi 速率 | 完全处于 2.4 GHz 时代,最大协议速率 192Mbps | 5GHz WiFi-6 已经普及,主流手机及电脑的协议速率均已经普及 2.4Gbps | 12.5 |
| 移动网络速率 | 3G 尚未普及,占比低于 50%,速率 200KB/S | 5G 几乎普及,速率 50MB/S | 250 |
我们见证了数据传输速度的跨越式发展:PCIe 5.0 协议实现了 64GB/S 的总线带宽,NVMe 固态硬盘的读写速度赶上了十年前内存的读写速度,随机读写性能已达到机械硬盘难以想象的水平,双万兆光纤也已经入户。然而,延迟并没有缩短多少——PCIe 5.0 协议层的 TLP 事务处理延迟仍然维持在纳秒级区间,NVMe SSD 的 4K 随机访问延迟(通常>100μs)与 DDR4 内存(约 15ns)仍存在三个数量级的差距。而在网络通信中,TCP/IP 协议栈的处理开销、网络设备的转发延迟,以及路由决策的时间消耗,都构成了无法仅依靠带宽提升来解决的系统瓶颈。这种延迟累积效应,使得终端用户在高带宽环境下的实际体验并没有获得数字倍数那么巨大的改善。
延迟:高性能计算真正的敌人
可能和大家的直觉不同,在高性能计算(HPC)领域,真正制约系统潜力的不是算力,不是带宽,而是延迟(Latency)。无论是分布式系统的跨节点通信,还是客户端到服务端的网络连接,再到芯片的每一次数据传输,延迟始终像幽灵般贯穿计算链条,吞噬效率、放大瓶颈。理解延迟的本质及其破坏性,是优化系统性能的第一步。
接下来,让我们从大往小,从宏观往微观,从系统架构到数据链路,从网络协议到 Kernel 设计,从磁盘到内存再到缓存,从主板电路到芯片构造推进,逐步探寻延迟对性能的巨大影响。
架构层面的延迟
光速极限
在跨地域强一致性场景中,光速限制是不可突破的物理边界。光纤的折射率约为 1.5,光在光纤中的传播速度为大约 20 万千米/秒。而北京上海直线距离 1088 公里,即便是拉一根笔直的线,再用超大发射功率发射器进行无中继传输,一步从北京打到上海,最低也需要 5.44ms 的延迟。现实中,北京至上海延迟最低的是金融专线,只能控制在刚刚 10ms 以下。
因此,我们一定要规避掉跨地域的数据库调用,否则每个写操作都要等待至少 20ms 的往返延迟,这是无法接受的。这种由宇宙基本常数决定的限制,迫使我们必须在结构层面进行妥协——要么采用最终一致性模型,要么使用地理位置进行系统分区,追求强一致性就只能“处处等”。
选择合适的分布式一致性等级
电商库存系统通过一致性分级可以实现性能跃升:支付环节采用预扣库存的强一致性模型(基于分布式锁实现 ACID 事务),库存展示则采用最终一致性模型(通过异步对账补偿机制保证 BASE 特性)。
异步化架构
当然,我们也可以使用终极大招——异步化改造。例如将同步 RPC 调用转换为消息队列的异步事件流(如 Kafka),再用背压机制(Backpressure)来控制生产消费的速率平衡,这样可以显著提升系统吞吐量。
虽然异步架构可以实现从“等待”到“非阻塞”的范式迁移,但是对流程的改动较大,调试难度很大,出问题了比较难修,需要权衡利弊,只在最合适的场景中使用。正如设计模式是面向对象对象编程范式对现实问题的妥协,异步架构也是图灵机模型对现实问题的妥协。
网络通信中的延迟
协议栈时延放大效应
网络协议栈的逐层封装机制会显著放大端到端延迟。典型的 HTTP 请求需要经历 TCP 三次握手(1.5 RTT)、TLS 密钥协商(1 RTT)等阶段,若遇 DNS 递归查询、反向代理、Keep-Alived 失效重连等情况,单次跨地域 API 调用延迟可能会突破 100ms。
RTT:Round-Trip Time 往返时延 。它表示一个数据包从发送端发出,经过网络传输到达接收端,再由接收端返回确认信息到发送端所需的总时间。Ping 命令输出的值就是 RTT。
传输层拥塞控制优化
高延迟网络中,传统 TCP Cubic 算法在慢启动阶段需多次 RTT 探测带宽,导致首帧渲染时间(TTFB)过长。采用 BBR(Bottleneck Bandwidth and Round-trip propagation time)算法可基于带宽与 RTT 实时建模,动态调整拥塞窗口,在低速网络中可以显著降低首次数据传输延迟。
用户态网络协议栈重构
传统内核网络协议栈因系统调用、内存拷贝(如 sk_buff 复制)导致高吞吐场景(单网卡大于 2Gbps)下性能上不去,远远跑不到网卡的极限。DPDK(Data Plane Development Kit)可以绕过 Kernel,在用户态接管网卡。如果配合使用轮询模式驱动(PMD)、大页内存与 NUMA 亲和性优化等方式,可以实现终极零拷贝网络包处理,单机可稳定处理 200Gbps 流量。
Kernel 的网络架构太落后了,在今天的网卡带宽面前显得性能很差,核心还是内存技术一直没有革命性的突破:数据接收需要 CPU 在用户态和内核态之间切换不止一次,这就要读写内存,而读写内存在 400Gbps 的网络洪流面前实在是太慢了,单通道 DDR4 内存的读写速度都不到 400Gbps。
除了系统软件层面的优化,硬件层面的优化也非常重要。
网络芯片创新
一种常见的硬件方案是采用专用网络处理器(NPU),通过异构计算架构来降低延迟。
- 将 TCP/IP 协议栈固化到 NPU 中,不再需要 CPU 来计算
- RDMA(远程直接内存访问)通过 Verbs API 实现应用层内存直接读写,绕过多层协议栈
- 大容量 SRAM(如 256MB 片上缓存)实现高频流表项本地查询
- 可编程流水线支持动态加载 P4 程序(SDN 中一种专为网络数据平面设计的编程语言),实现微秒级协议转换
- 卸载 TLS 加解密功能到 NPU 中,可以显著加快 TLS 握手速度
物理层传输介质革新
空芯光纤(Hollow-Core Fiber)通过空气介质传输光子,相较传统石英光纤(折射率 1.44)将光速提升 30%,伦敦至纽约金融专线使用这项技术让延迟降低了 5ms。
光子集成电路(PIC)在硅基衬底上集成激光器、调制器与波导,绕过整个“光电转换 - 以太网 - TCP/IP”技术栈,直接在芯片间实现 Tbps 级的光互连,可以将光模块的传输延迟从 3ns 压缩至 200ps,这对超算集群的性能来说至关重要。超级计算机最大的瓶颈就是信息传递的速度,光通信的技术创新将是下一个十年人类攀登超级计算机高峰的利器。
CPU 到内存的延迟
当系统架构与网络优化将延迟压缩到物理极限时,CPU 与内存之间的“最后一公里”就成为了新的战场。现代 CPU 的时钟周期以纳秒(10⁻⁹秒)为单位,而访问内存的延迟却高达百纳秒级——这相当于战斗机驾驶员要等待三分钟才能获得雷达扫描结果,饥渴的 CPU 在等待中浪费了 99% 的计算潜力。
当前 x86 服务器和 PC 上最常用的 DDR 内存技术,在主板设计时却把“内存条数量可随时增减”设为了第一设计目标,而不是限制内存条的配置形式来降低延迟。你看苹果就很聪明,M1 芯片起手就是 Unified Memory 统一内存——直接把 LP-DDR 内存芯片封装在 CPU 芯片的基板上,在物理上降低内存延迟。你说消费者可选的内存配置有限?那是消费者的问题,跟我苹果有什么关系 :D
网络通信是一种可以兼容任何延迟、任何速率的通信技术,随之而来的便是从硬件到软件的复杂。而计算机最基础的硬件通信,如 DDR 内存,PCIe 总线等技术,为了能够和 CPU 进行标准化的超高带宽通信,并保持简单和低成本,会在硬件层面进行标准化设计。例如 DDR 内存就需要保证 CPU 到每一根内存条上的每一个 bank 的延迟(时序偏移)要非常严格地固定,误差要极低,否则就会出现内存错误。这是因为 DDR 内存依赖严格的时序控制,会在时钟的上升沿和下降沿进行两次数据传输。
另外,DDR 内存在通电后其实是一直在不停地自行刷新(充电)的,全部内存行加在一起的刷新周期通常为 64ms,因为存储信息的电容一直在漏电,时间长一点数据就没了,这种充电刷新机制也在极限场景下限制了 DDR 内存的最低读写延迟。
CPU 到缓存的延迟
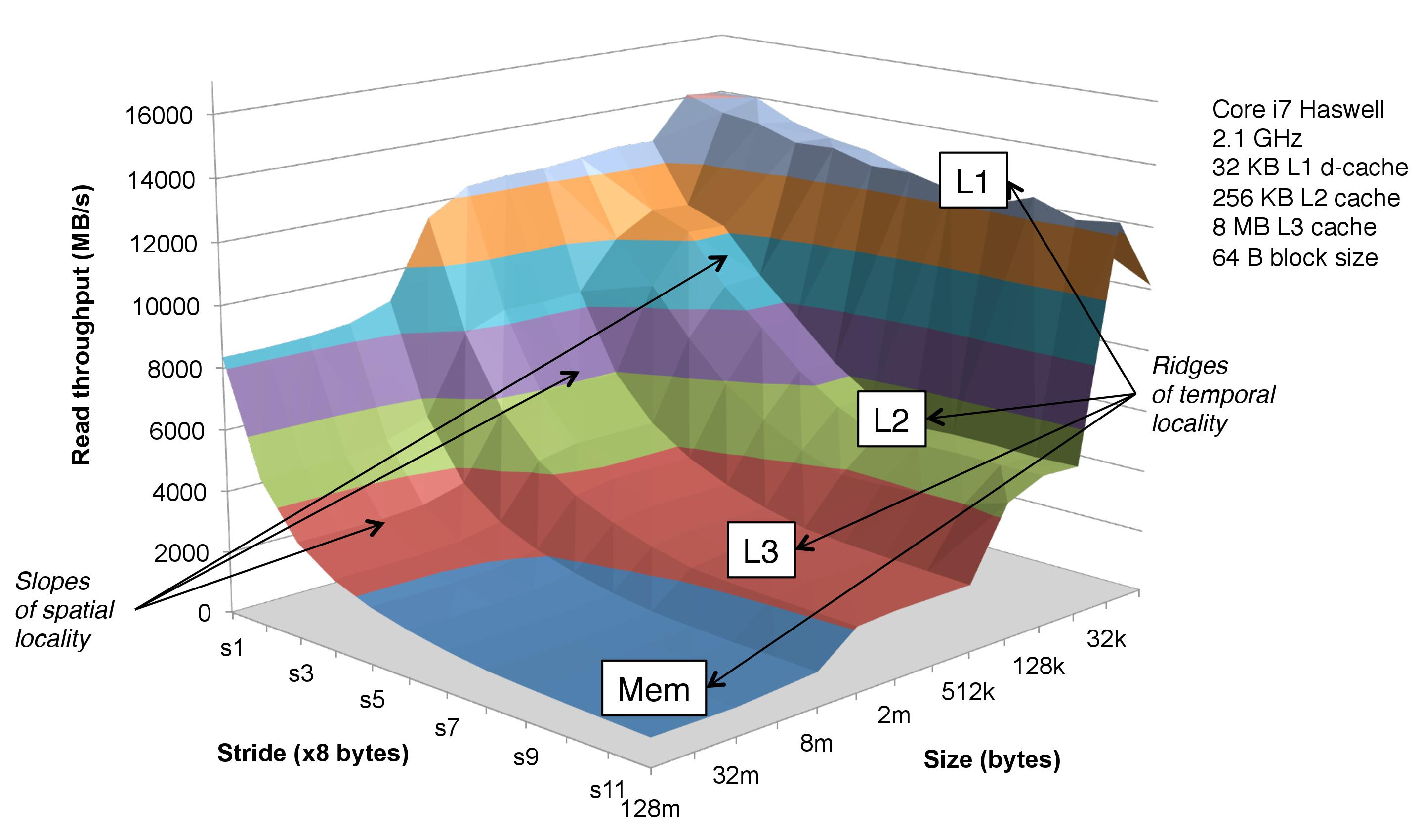
现代 CPU 架构本质上是一个「内存延迟补偿装置」,其缓存层级设计堪称计算机工程史上最精妙的空间换时间案例:
L1 缓存:分为指令缓存、数据缓存,3-4 周期访问延迟,容量仅数十 KB。其访问速度与寄存器相当,但程序员必须像布置雷区般谨慎,想吃到 L1 缓存的性能,需要严格控制每一个程序块中的变量大小和数量。一般为单个 CPU 核心独享。
L2 缓存:12-15 周期延迟,容量数百 KB。一般为单核心独享或者少量核心簇共享
L3 缓存:一般为芯片 Die 中所有核心共享,30-50 周期延迟,容量数十 MB。AMD 通过 3D V-Cache 技术,让八核 CPU 的三级缓存达到了 128MB,成功在游戏场景中登顶,彻底打破了持续了十多年的“i3 默秒全”噩梦。
这里需要提一嘴,上一次 AMD 打游戏比 Intel 强还是 K8 架构,那一年,AMD 首次把内存控制器从北桥芯片吸收到了 CPU 内部,大幅降低了内存延迟,而当时英特尔掏出来的却是高频低能的奔腾 4,AMD 实现了首次性能登顶。那其实也是一个低延迟打败高频率的故事。
内存墙困境:即使是最快的 DDR5-6400 内存,访问延迟仍在 70ns 以上。当发生缓存未命中时,CPU 流水线会像突然断油的发动机那样陷入空转——内存一日,CPU 一年。
NUMA 架构的局部性:在 4 路 NUMA 服务器中,访问远端内存节点的延迟是本地访问的 2.3 倍。
TLB 击穿:当进程虚拟地址空间超过 TLB 缓存容量时,每次内存访问都需要多级页表查询。为了避免这问题,我们可以采用大页内存技术,这在 Redis 持久化场景中十分有用。
分支预测赌博:现代 CPU 的分支预测准确率可达 95% 以上,但预测失败的惩罚高达 15-20 周期。
SIMD 高级指令集:将循环操作转换为 SSE/AVX 指令,不仅提升吞吐量,更能减少指令解码延迟。ClickHouse 的聚合操作(如 SUM、COUNT、AVG 等)大量使用了 SIMD 向量化指令集,达成了“性能随 CPU 核心数量线性增长”这一可怕成就。例如 AVX512 指令集可以在一个时钟周期内完成 32 次双精度浮点数的计算,或者 64 次单精度浮点数的计算。
那么,SIMD 指令集看起来已经是最适应 AI 时代的计算工具了,为什么现在英伟达能冲上美股是指第一名呢?因为皮衣刀客老黄是真的有两把刷子,从大规模矩阵并行计算到硬件低延迟高带宽互联,最近一些年的英伟达 GPU 就是为 AI 而生的,打游戏早就成了副业。下面我们摊开好好学习一下。
GPU 读写数据的延迟
在通信原理中,延迟和带宽是没有必然联系的两个技术属性。但是在现实世界的硬件设计中,大部分硬件其实是部署在一个二维平面上的(少数是三维),而电流的速度又无法超过光速,这就决定了硬件设计的一个基本原则:带宽换延迟,延迟换带宽。
显存的高带宽其实是高延迟换的
GPU 的 GDDR 显存采用了与传统 DDR 内存完全不同的设计理念——牺牲延迟以换取超高带宽。GDDR 显存的单颗粒数据位宽仅为 32bit,远低于 DDR 内存的 64bit (ECC 模组为 72bit),但通过极高的工作频率 (目前最新的 GDDR7 单引脚数据传输速率已达到 32Gbps),配合更多的 Bank 并发访问,最终实现了数倍于 DDR 内存的带宽。这种设计完美契合了 GPU 的应用场景 - 大规模并行计算往往更依赖内存带宽而非单次访问延迟。
为了进一步缓解显存访问延迟的影响,GPU 采用了细粒度、低开销的线程切换机制。当一个线程组 (Warp) 在等待内存访问时,GPU 可以在一个时钟周期内切换到另一个就绪的线程组继续执行,这种超细粒度的线程切换几乎没有开销。配合 GPU 庞大的线程并发能力 (一个 SM 可以同时管理数千个线程),使得 GPU 能够有效隐藏内存访问延迟。这种设计与传统 CPU 的上下文切换形成鲜明对比 - CPU 切换线程需要保存/恢复大量寄存器状态,开销巨大。
DDR 内存在某种程度上就像是落后的并口硬盘,而 GDDR 才是串口,是新技术,依靠高频取胜!
下一步,适用于大模型推理的显存可能会是混合显存架构,将 HBM3(4096bit/6.4Gbps)与 GDDR6(256bit/18Gbps)组合,在保持整体高带宽的同时,让热数据的访问延迟降到更低。MOE 混合专家架构就很适合这个方案来提速:全量模型放在 GDDR 中,而被激活的专家放在 HBM 中。
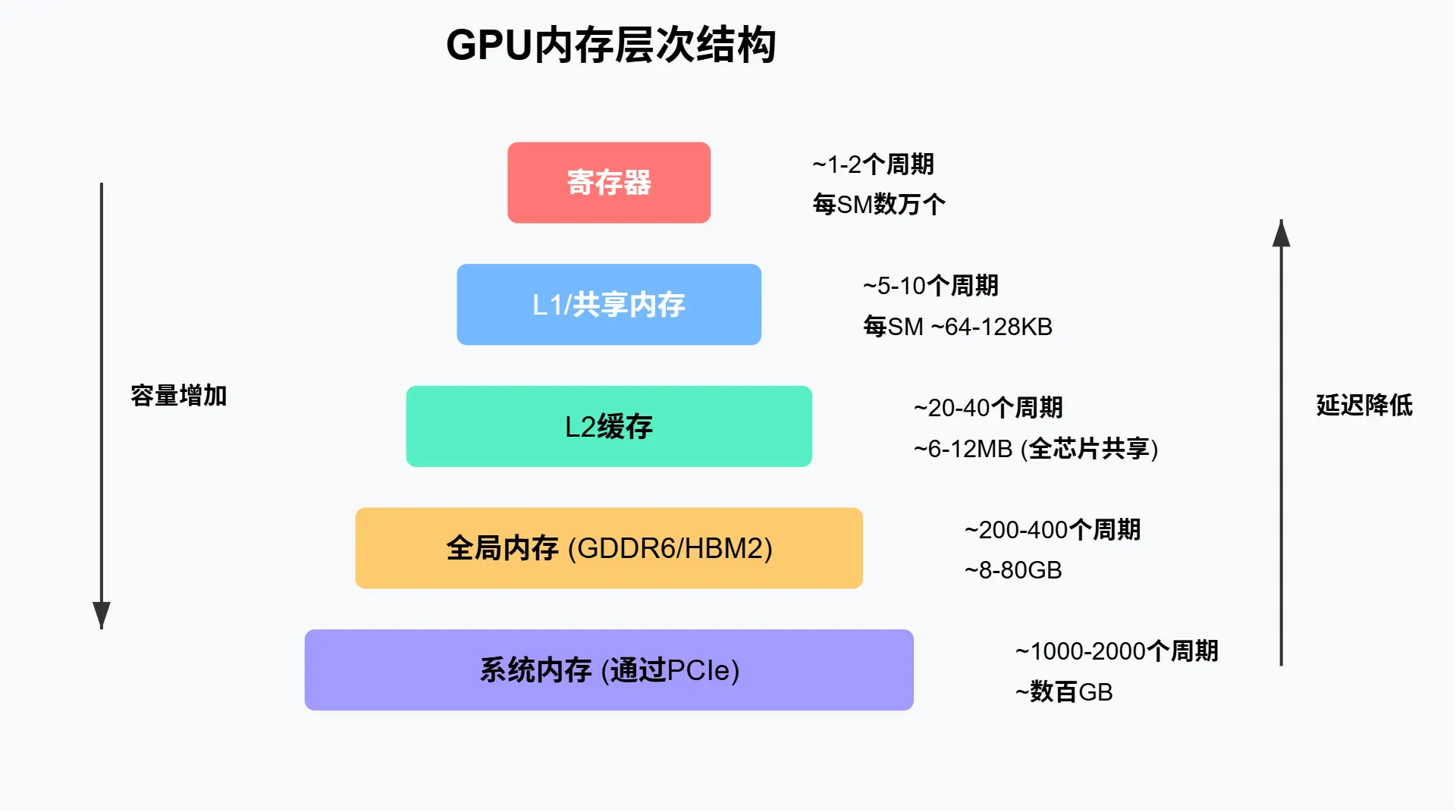
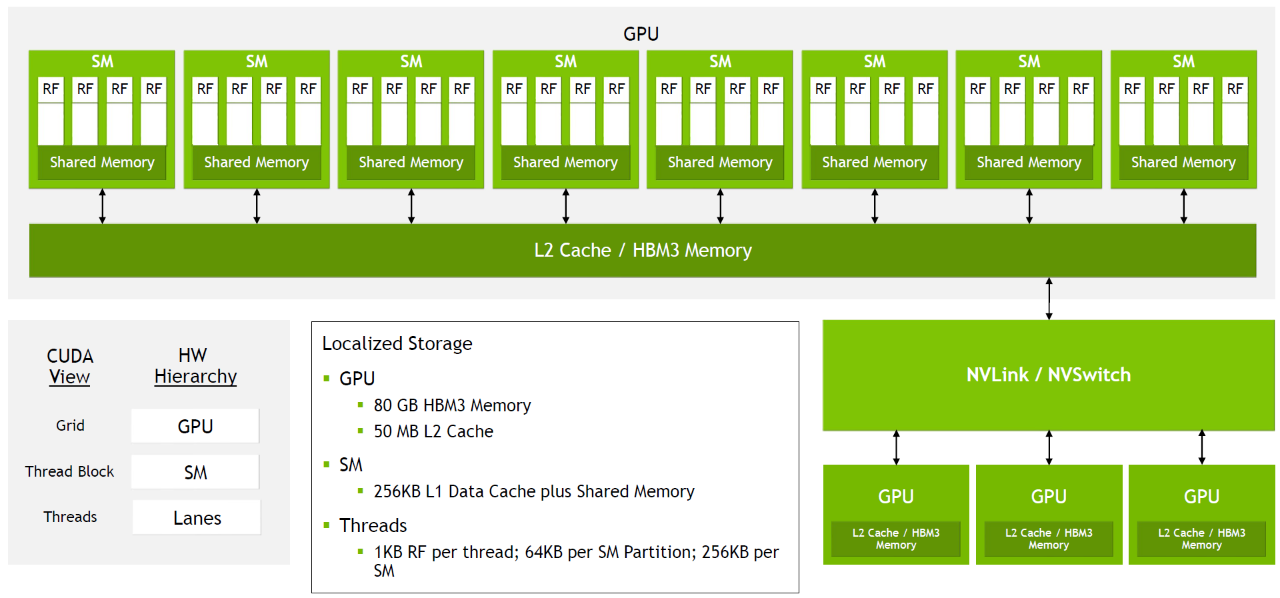
GPU 内存层次结构解析
现代 GPU 采用多级内存架构,从寄存器到全局内存,每一级都有特定的容量与访问速度特征。以 NVIDIA Tesla V100 为例,每个流式多处理器 (SM) 拥有 65536 个寄存器,配合 256KB 的 L1/共享内存和全 GPU 共享的 64MB L2 缓存,最终连接到 32GB 高带宽 HBM2 全局内存。
数据访问路径决定了计算性能——从寄存器到 CUDA 核心的数据移动最快,而从全局内存到计算单元则需穿越多层缓存,产生明显延迟。GPU 内存架构特别优化了 32 线程为一组的访问模式,以 128 字节为单位的缓存行设计,能够同时为 32 个线程提供 4 字节操作数。
GPU 通过"延迟隐藏"机制来克服内存访问延迟。当一个线程束因等待内存而停滞时,硬件调度器会立即切换到其他就绪的线程束继续执行。这种细粒度的多线程交织执行,配合合并访存等优化手段,有效掩盖了内存访问的高延迟。从本质上看,GPU 内存层次结构就是围绕着“总平均延迟最低”而非“单次延迟最低”来设计的。
实际上,显存的带宽已经到达了显著的硬件制造瓶颈,当下大模型的优化重点已经从加速矩阵计算深入到了“保持效果的低精度数据表示”和“超大规模并行计算”上。
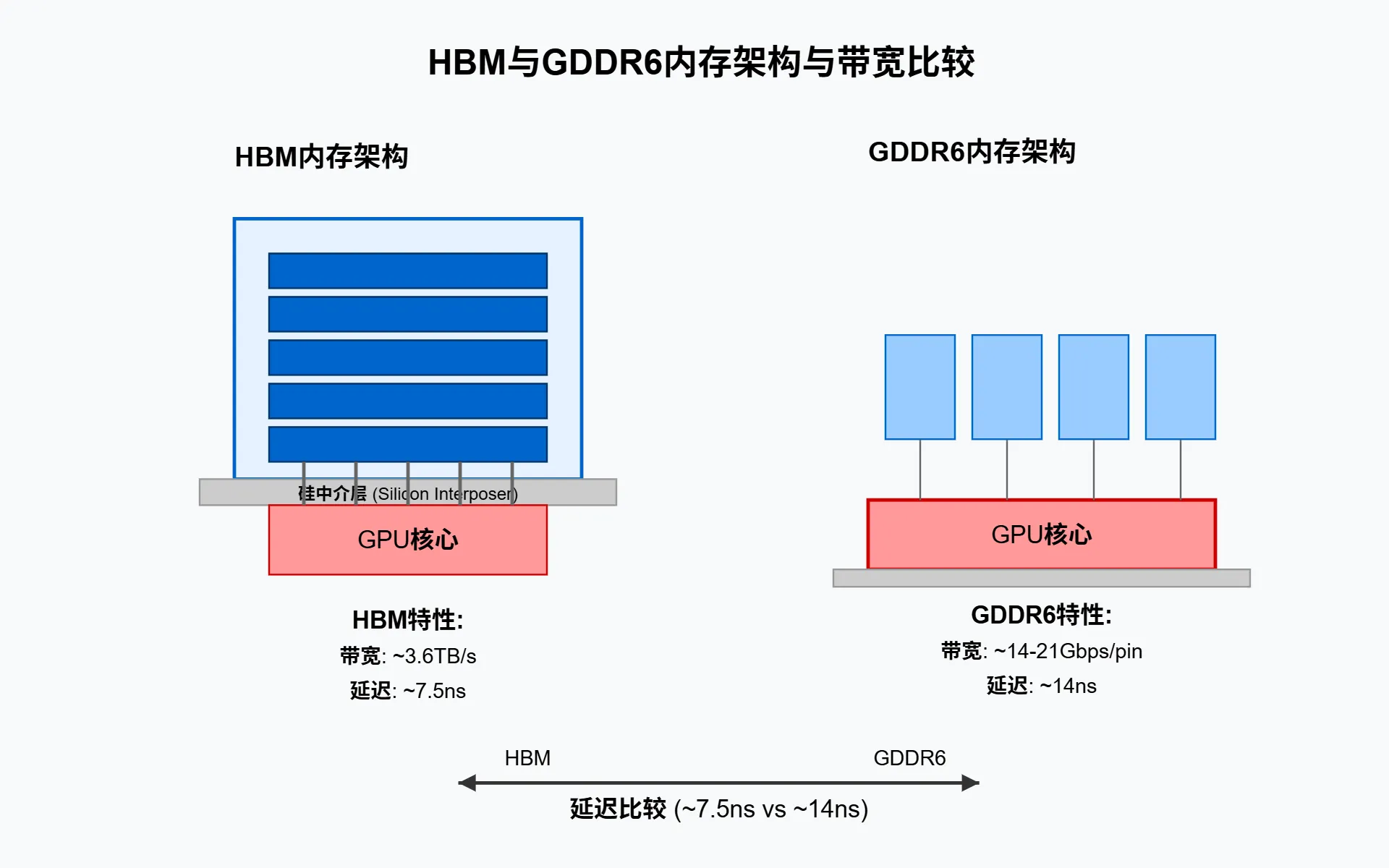
HBM 与 GDDR6 等高带宽内存技术
在现代 GPU 架构中,内存带宽已成为决定性能上限的关键因素。HBM (High Bandwidth Memory) 和 GDDR6 是两种主流高带宽内存技术,它们采用截然不同的设计理念来解决带宽瓶颈问题。
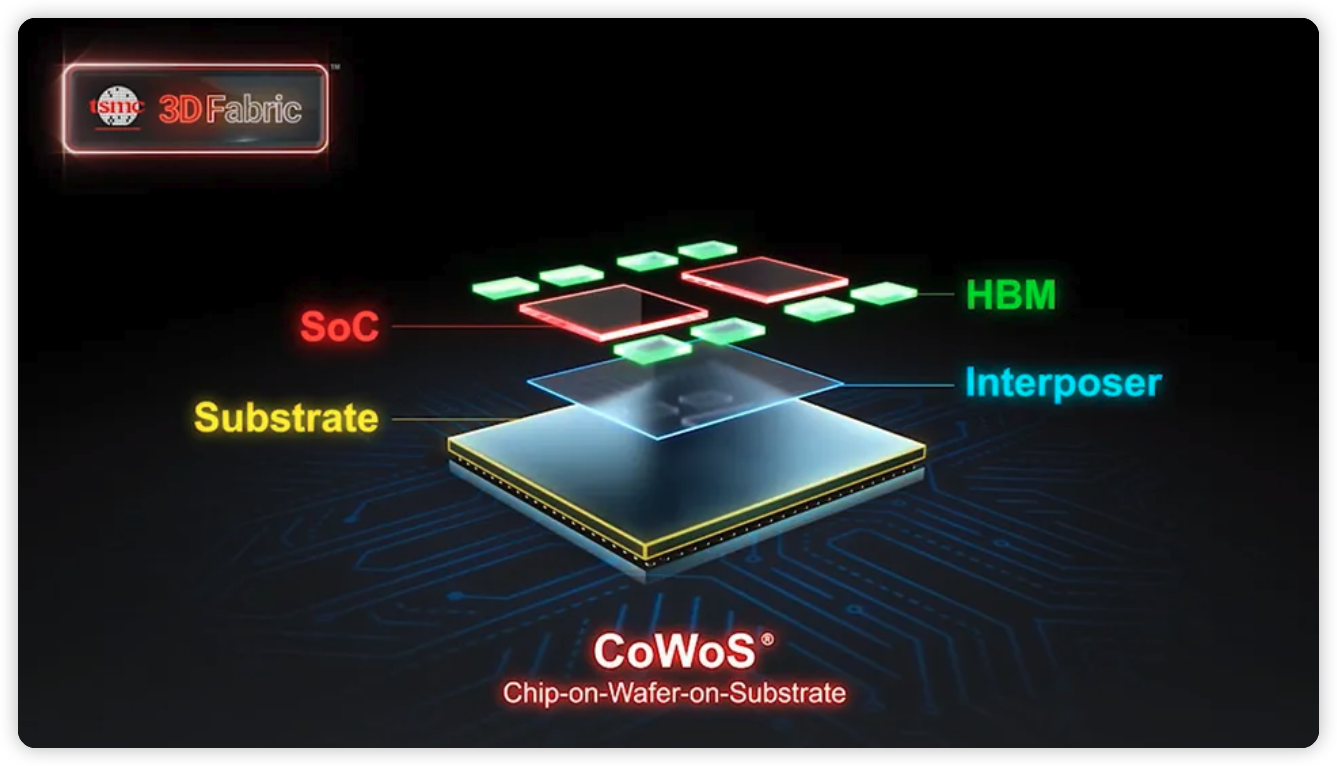
H100 计算卡的核心部分,除了芯片,还包含 HBM3 高速显存,他们之间通过台积电的 CoWoS 技术封装在同一块基板上。HBM 内存的低延迟和超高带宽,是 H100 高算力的最大贡献者,芯片规模以及台积电的先进制程的贡献反而要更低一点。
HBM 采用 3D 堆叠设计,将多个 DRAM 芯片垂直堆叠并通过硅通孔 (TSV) 互连,显著缩短了信号路径。以 NVIDIA Tesla V100 为例,其 HBM2 配置包含四个堆栈,每个堆栈八颗内存芯片,提供高达 900GB/s 的峰值带宽。而最新的 H100 采用 HBM3 技术,带宽更是达到惊人的 3TB/s。相比之下,GDDR6 采用传统平面布局但通过更高的时钟频率和更宽的总线宽度提升带宽。在 RTX 系列最新的 GPU 中,GDDR7 可提供约 1TB/s 的带宽。
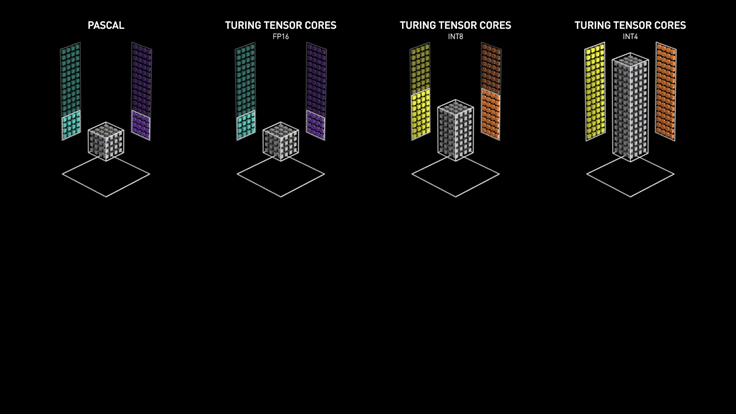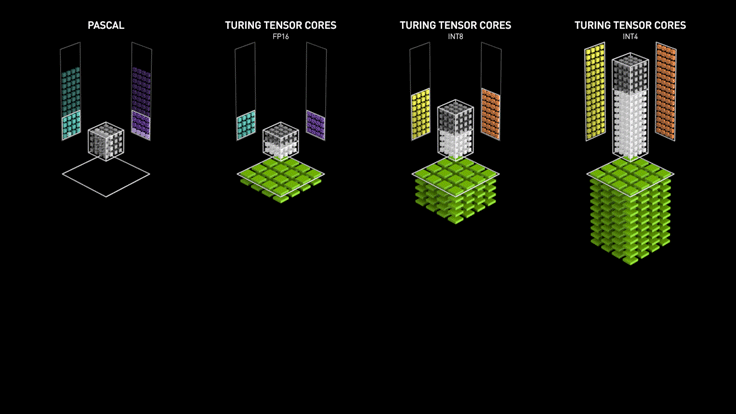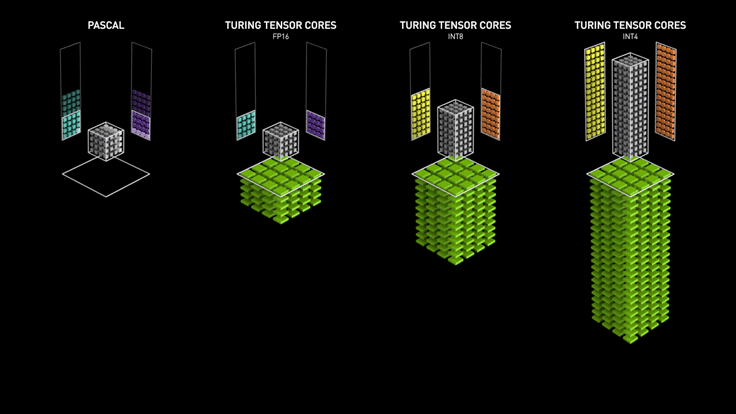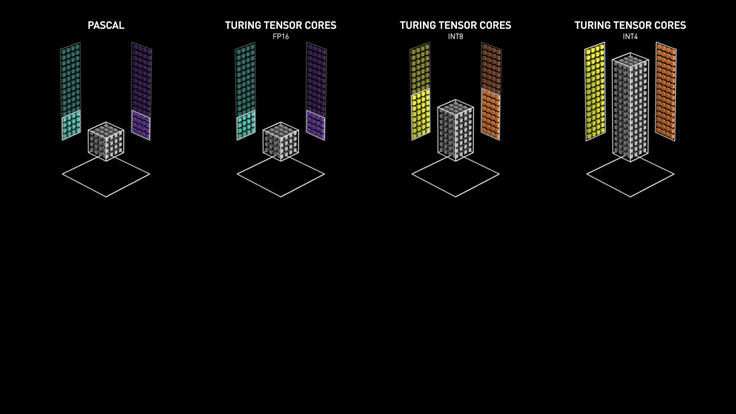
而由于 HBM 内存芯片离 GPU 芯片更近,所以延迟大约只有 GDDR 的一半。此外,当模型量化从 FP32 降至 FP8 时,不仅计算速度提升,更重要的是通过带宽瓶颈的数据量减少了 75%,这解释了为何 H100 的 FP8 格式能显著加速大模型训练与推理。
其实计算机科学没有银弹,带宽的计算公式其实非常简单:位宽 x 频率。位宽就是“一次性读取的数据量”,位宽需要在底层的电气性能设计和硬件制造上下很大的功夫才能提升一点点,而增加频率却可以通过压缩半导体的制程来较为容易地实现,就像当初放弃并口硬盘改为串口硬盘那样,位宽的增长总有极限,信号串扰,光速牢笼带来的通信延迟,以及三维宇宙的空间限制都是阻碍位宽无限增长的枷锁。
PCIe 通道瓶颈与 NVLink 高速互连技术
PCIe 通道长期以来一直是 GPU 与 CPU 之间数据传输的主要瓶颈。以 PCIe 3.0 x16 为例,其 32GB/s 的双向带宽在大规模数据传输场景下显得捉襟见肘。为了突破这一限制,NVIDIA 推出了革命性的 NVLink 高速互连技术。以 Tesla V100 为例,其配备 6 条 NVLink 2.0 通道,每条通道可提供 50GB/s 带宽,总计可实现 300GB/s 的惊人带宽。
在实际部署中,如 IBM AC922 服务器,每个 V100 GPU 通过 NVLink 获得 150GB/s 与主机的带宽连接,同时 GPU 之间也可通过 NVLink 直接进行高速通信。这种架构不仅大幅降低了通信延迟,还能有效支持大规模深度学习训练等数据密集型工作负载。对于需要频繁在 CPU 和 GPU 之间移动数据的应用来说,NVLink 的高带宽特性至关重要,可以充分发挥 GPU 的计算潜能。
NVLink 不仅提供更高带宽,其延迟性能也优于 PCIe。这对于延迟敏感的应用尤为重要,如大规模 AI 模型训练中的梯度同步和推理过程中的批处理。
所谓的 CUDA 霸权,表面上看是 AI 训练中生态软件的接口依赖,但本质上还是其他公司太菜:大模型训练的瓶颈从来就不是单颗芯片的计算容量,而是多卡互联,协同计算的效率。
NVIDIA HGX H100,由 8 个 H100 SXM5 模块加上 4 个 NVSwitch Chip 在同一个 system board 上,NVSwitch Gen3 芯片其实是英伟达给出的硬件级多卡互联超低延迟解决方案。
异步数据传输与预取机制
现代 GPU 架构通过 NVLink 等高速互连技术显著提升了带宽,然而,即使有高带宽,数据传输的延迟成本仍然不可忽视。解决这一问题的核心策略是数据传输与计算的重叠执行。通过 CUDA 流 (streams),我们可以在某批次数据计算的同时,异步预取下一批次所需数据。这种方式有效隐藏了传输延迟,保持计算单元的高效利用。
在实际实现中,预取机制更为精细。例如,在处理长上下文生成时,可以每 16 次迭代批量发出预取操作,然后逐个检索结果 4。这种策略在某些基准测试中能将 FP32 内核的性能从 140 微秒提升到 75 微秒,显著加快 token 生成速度。
对于大规模数据处理,如 LLM 推理,合理利用预取和异步传输可以将数据传输开销最小化。特别是当使用 HBM3e 等高带宽内存技术时,如何把 1228GB/S 的带宽跑满才是第一个要解决的问题,DeepSeek 团队就深谙此道。


发表评论: