高并发的哲学原理(八)-- 将 InnoDB 剥的一丝不挂:B+ 树与 Buffer Pool
《高并发的哲学原理 Philosophical Principles of High Concurrency》开源图书已经发布,简称 PPHC。地址:https://github.com/johnlui/PPHC
前面几篇文章,我们大多数时候都在挥舞着架构大棒,对性能问题进行降维打击,但是本文不一样,本文要啃硬骨头:吃透 MySQL 的 InnoDB 存储引擎,以便于我们能顺利地看懂下一篇文章。
同时,本文也是一篇比较完善的讲解 InnoDB 底层设计原理的文章,单独作为 InnoDB 的一篇详解文章我认为也是极好的,如果大家觉得对身边的人有帮助,可以单独分享此篇文章,相信能够让每一个读过的人都对 InnoDB 有新的理解、体会和感悟。
本文将是《高并发的哲学原理》系列中唯一一篇有点像面试八股文的文章,但是,我们还是要尽量走出个虎虎生风,走出个一日千里,再走出个恍如隔世...... 下面我们正式开始。
磁盘存储引擎的巅峰——InnoDB
发展历程和设计目标
2004 年,扎克伯格选择了 MySQL 来创建 Facebook,不承想,Facebook 迅速火遍了全世界。之后的十年,Google、亚马逊、阿里巴巴等互联网巨头纷纷选择了 MySQL 作为自己的核心数据库,随之而来的就是 MySQL 的高速发展:互联网巨头投入海量技术资源把 MySQL 打造成了一个十分优秀的开源数据库软件,而 InnoDB 就是承接资源最多的那个部分。
这些公司的数据库需求基本都是一个类型的:表字段很少,但是行数很多;对于单个查询的时间要求很高;很少存储长字符串和二进制文件。这个类型的需求恰恰不是传统数据库(如 Oracle)的强项。而且,互联网公司的发展一日千里,无论是授权费还是实施速度,买 Oracle 都不如自己魔改 MySQL。之后的十几年,MySQL 特别是 InnoDB 的发展真的可以说是虎虎生风、一日千里,如果你站在 2014 往回看 2004,也确实称得上恍如隔世。
但 InnoDB 也不是银弹,它的性能也是靠取舍得来的。
InnoDB 拿什么找信息之神换了什么?
InnoDB 和之前的 MyISAM 比,最大的变化就是将磁盘上面数据的基本存储结构从索引+数据这样的分体式,变成了所有数据都挂在索引上的整体式:从“B+ 树索引”加“磁盘连续存储数据”(中间用指针链接)变成了“B+ 树存储全部索引和数据”。
这个操作给 MySQL 带来了翻天覆地的变化。那么,InnoDB 到底做了哪些取舍呢?
代价
- 插入性能显著下降,更新性能显著下降(100~1000倍,但是绝对耗时依然在毫秒级别)
-
一次性读取连续多行的复杂度大幅提升(大约提升了
行数/10那么多倍) - 因为事务隔离导致大表 count(*) 的返回时间令人崩溃(多少倍已经无法衡量,一千倍到一千亿倍吧)
- 放弃了数据完全压缩能力(磁盘占用 2-5 倍)
- 写入放大显著增加,对磁盘特别是固态磁盘(SSD)形成了额外的压力
收益
-
支持了事务:事务是极其核心的功能进步,使 MySQL 摆脱了玩具定位,真正实现了
ACID,成为了一个合格的 OLTP 数据库 - 大表的单行读取性能暴增:数据挂在 B+ 树索引上带来的优势,还可以依靠内存缓存进行加速和局部性优化
- DML(表结构变更)操作的安全性大幅提升,数据损坏的概率大幅降低
- 联表查询性能大幅提升,让 MySQL 在 OLAP 方向也有很大进步
- 支持全文检索:类似于 ES 的倒排索引
- 其它小收益:支持了行锁、内存缓存、外键约束等
这些代价和收益,基本都是两个东西带来的:B+ 树和 Buffer Pool,下面我们分别认识一下这两个技术。
B+ 树
B+ 树是 1970 年 Rudolf Bayer 教授在《Organization and Maintenance of Large Ordered Indices》一文中提出的,此后,该技术迅速成为了海量数据存储与检索的大宝贝:以查询为主要场景的关系型数据库,无一例外地选择了它。
B+ 树基本思想
B+ 树是一种平衡多路查找树,它的思想其实是承袭自平衡二叉树和 B 树的,但是它是为速度非常慢的所谓“外存”设计的一种数据结构,所以它拥有独特的设计方向:
尽量减少数据不停增长时的磁盘 IO 数量:包含插入新数据场景和查询场景
它将经典平衡二叉树的“再平衡”过程颠倒过来了:最底层的叶子结点致密排列,新增数据时不断新增新的叶子节点,需要进行“再平衡”操作的不是叶子节点,而是上面的索引页,索引页具有以下特点:
- 索引页的数量很少
- 再平衡时 B+ 树算法调整的索引节点数量也很少
- 索引容量足够大:3 层索引可以承载 2000 万行数据,4 层索引可以承载 200 多亿行
- 索引页少,就可以将所有索引全部载入内存,读取索引的磁盘 IO 无限趋近于 0
InnoDB 是如何组织数据的
下面我们来具体认识一下 InnoDB 中索引和数据在磁盘上是怎么利用 B+ 树思想进行组织的:
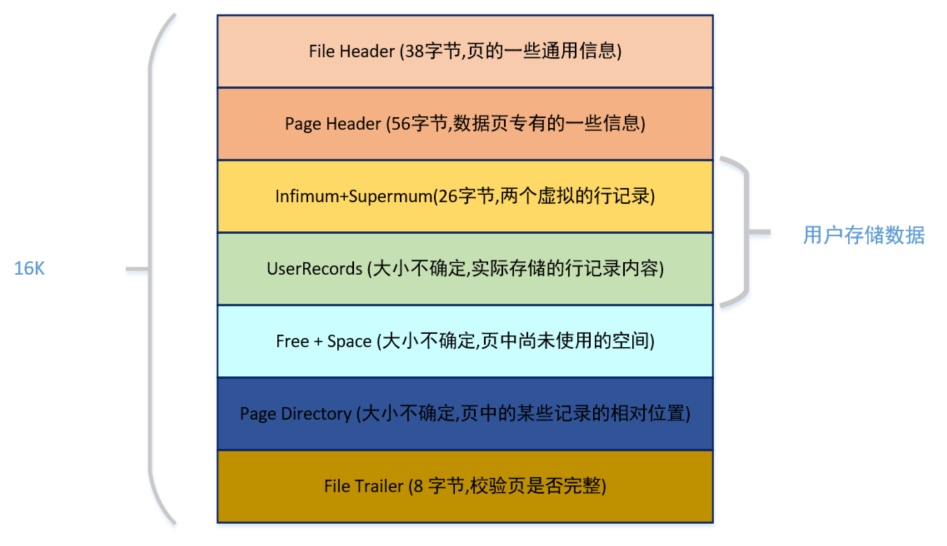
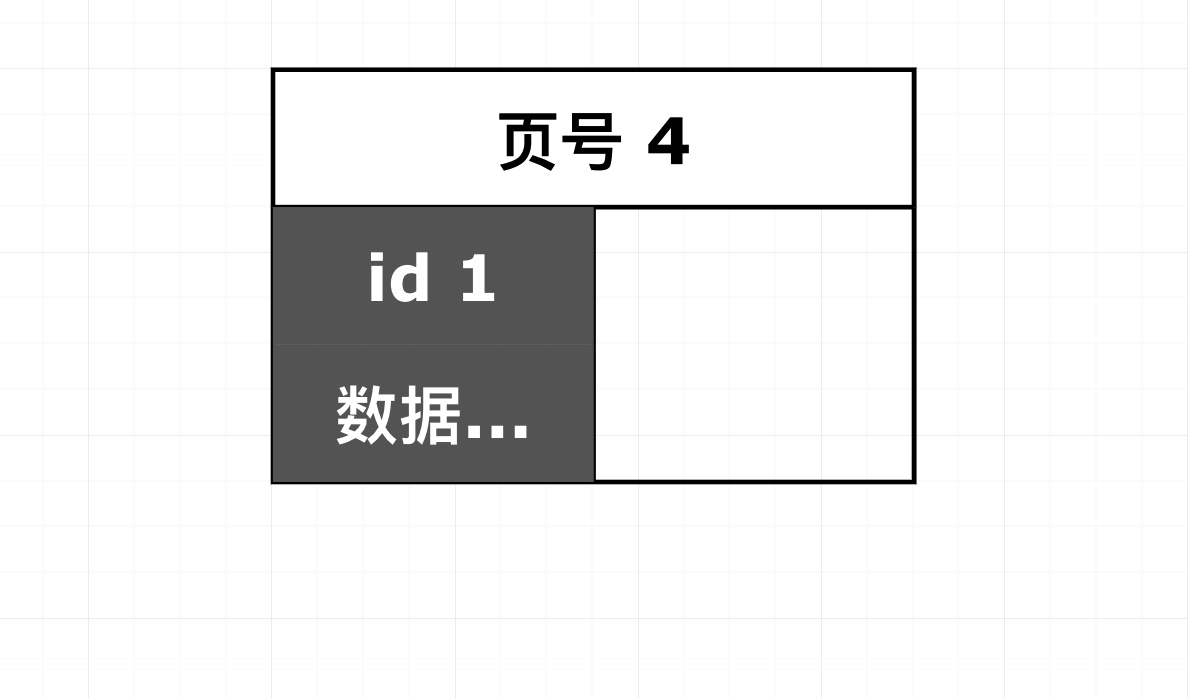
1. 页
页是 MySQL 中数据存储的基本单元,整颗 B+ 树就是一个又一个相互使用指针连接在一起的页组成的。由于 InnoDB 出现的时候,SSD 还没有出现,所以它是为了机械磁盘及其 512 字节的扇区而设计的,所以页块的默认大小被设置为了 16KB(32 个连续扇区)。

这张图基本展示出了页之间的指针关系:
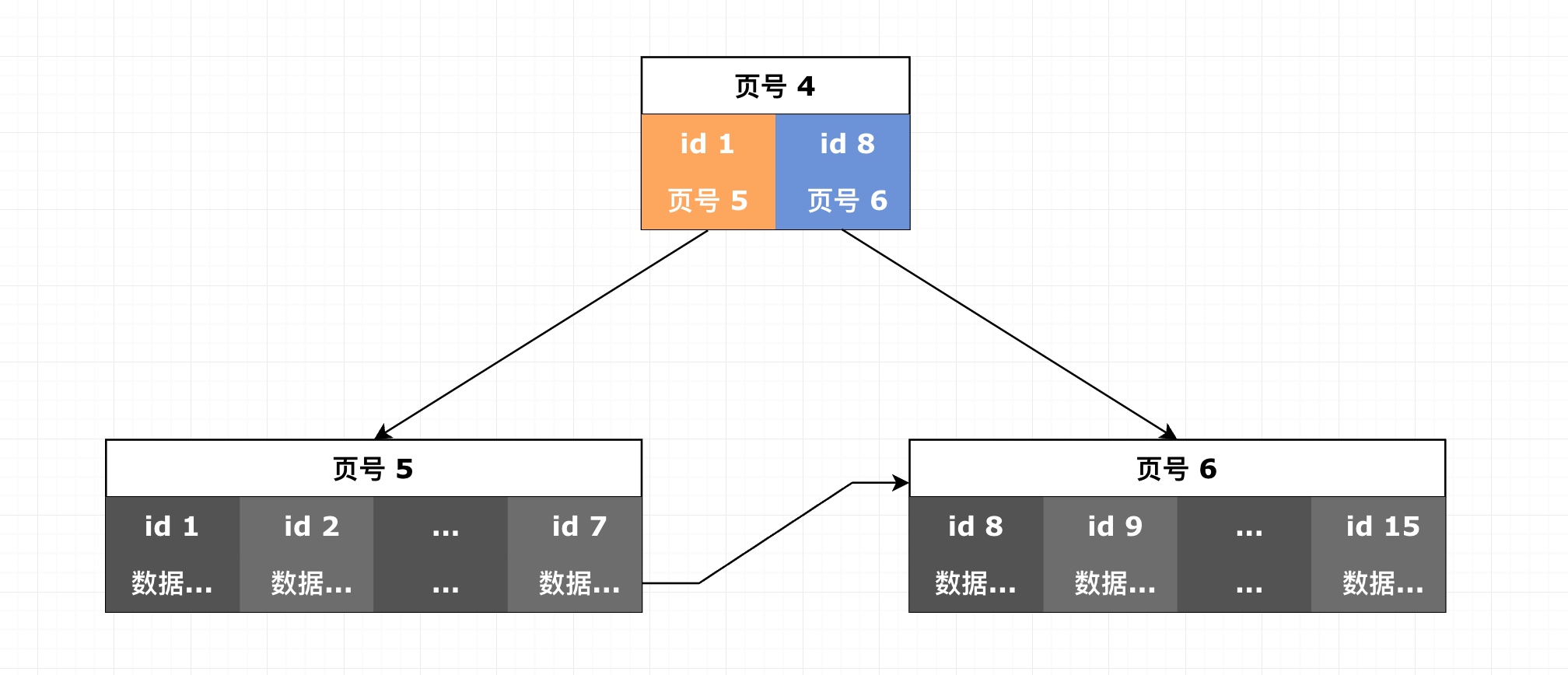
-
上层页对下层页拥有
单向指针 -
同一层内相邻的页之间拥有
双向指针,无论是上面的索引页层还是底层的数据页层 -
最底层数据页层中,每一页可以存储多行数据,每一行数据拥有指向下一行的
单向指针
而在物理层面,每一页的内部结构都如下图所示:
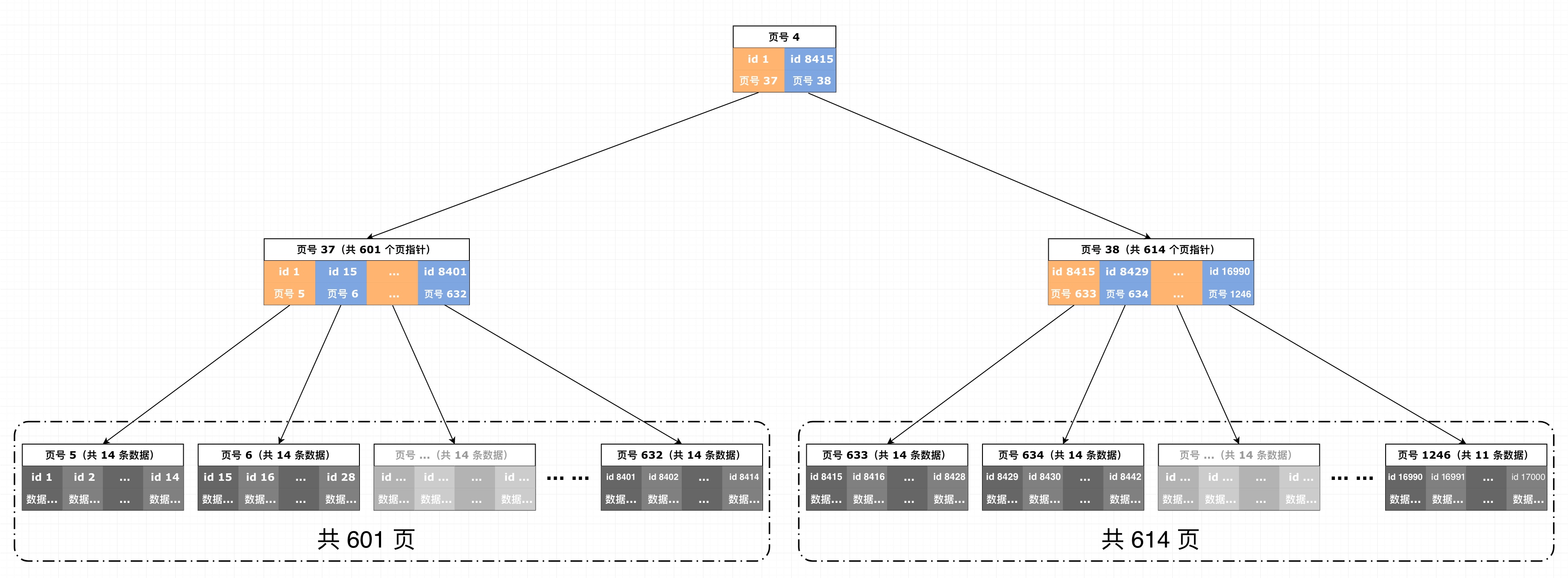
2. 索引页里面有什么
我们用更清晰的二层索引簇结构来展示索引页包含的关键信息,顶部那个彩色的就是索引页。
除了头部和尾部的基础信息字段之外,索引页的“用户存储数据”紧密排列着指向下一层页的指针,结构为:id|页号。
这里的 id 就是这张表默认主键的那个 id,一般为int(4 字节)或者bigint(8 字节)。该数字的含义是:
该页号对应的页,以及下挂的所有页,所拥有的全部数据行中,id 最小的那行数据的 id
InnoDB 使用这个数字可以快速定位某一行数据所处的页的位置。
页号就是页的编号,在不同版本的 MySQL 上这个页编号的长度是不一样的,下面我们会通过测试来确定 MySQL 8.0 中页编号的长度。
3. 数据页里面有什么
B+ 树上层的所有页只存储索引,只用最底层的页存储数据。这是 B+ 比 B 树优秀的地方:以一丢丢写入速度为代价,让较少的索引层数内存下了更多的索引指针,可以支撑海量的数据行数。
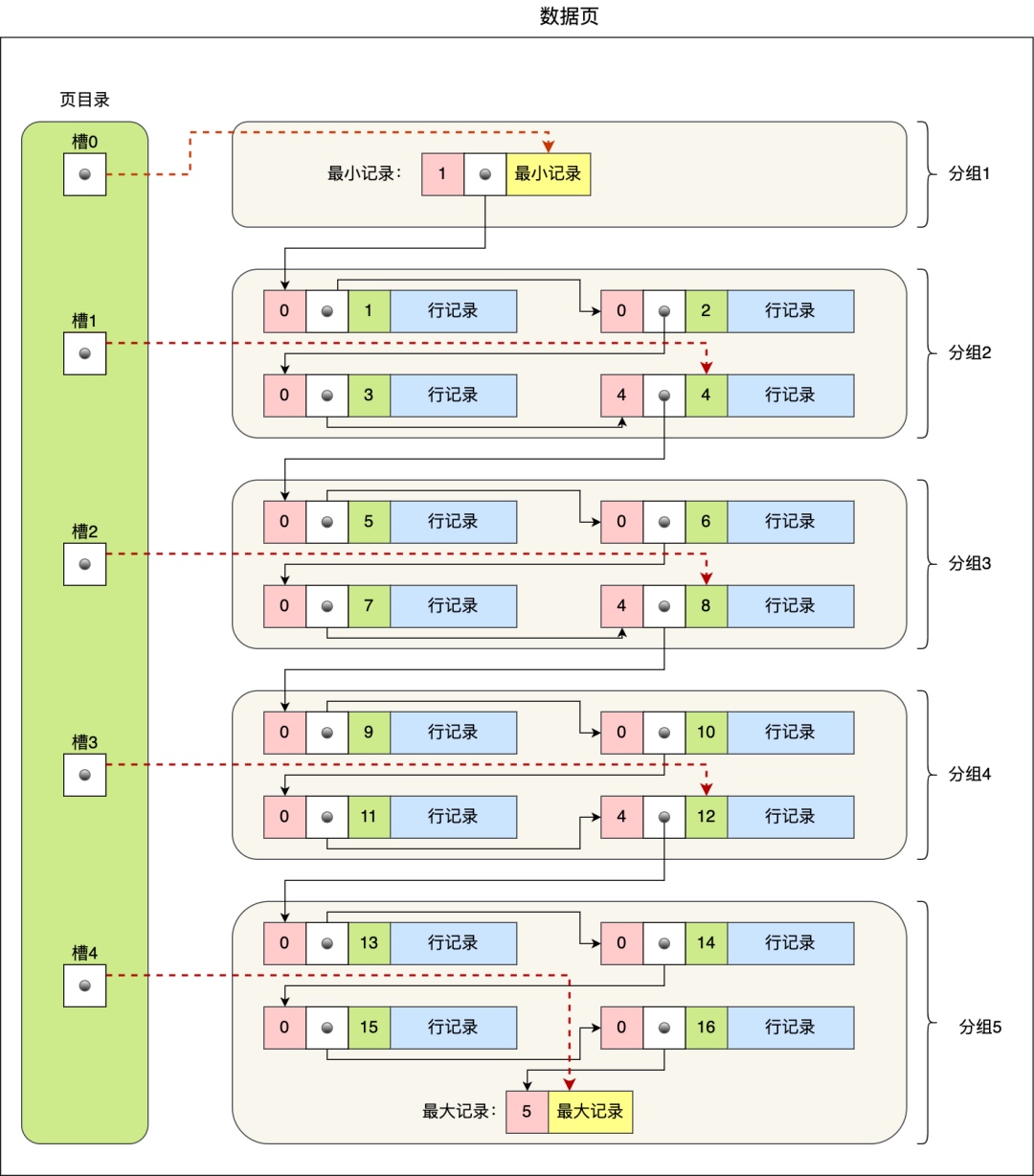
数据页内部是分槽的,相当于自己又加了一层索引。数据页内部拥有最小记录指针和最大纪录指针,有没有觉得一花一世界,数据页内部结构和 B+ 树颇有几分神似呢?
执行 select * from users where id=6
有了前面的铺垫,真正的 SQL 查询过程就呼之欲出了:我们要找出id=6的一行数据时,只需要一层一层地比大小:
-
将顶部页(16KB)的数据读入内存,将 6 和每一个
id|页号进行大小对比,找到 6 落在哪一页:大于等于当前 id 并小于右侧邻居的 id - 将上面找出的那一页数据读入内存,重复上面的比对操作,直到找到最底层的那个数据页
-
将数据页读入内存,找出
id=6索引下下挂的全部数据,就是这一行数据
InnoDB 数据插入测试
下面我们针对 InnoDB 搞一次数据插入测试,希望能够窥探到 InnoDB 索引页“再平衡”的具体操作,追踪索引扩层的具体动作,确定id|页号中页号的数据长度,并顺便解决一下“2000w 行分表”问题的历史悬案。
神奇的“2000W 行分表”历史悬案
相信大家都听说过“单表到了 2000 万行就需要分表了”,甚至有人还看过“京东云开发者”的那篇著名的文章¹,但是那篇文章为了硬凑 2000 万搞出了很多不合理的猜想。
下面我们实际测试一下 MySQL 8.0.28 运行在 CentOS Stream release 9 上(文件系统为 ext4),索引层数和数据行数之间的关系,相信测试完以后,你会对这个问题有深刻的理解。
测试准备
测试表结构如下:
CREATE TABLE `index_tree` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`s1` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's1',
`s2` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's2',
`s3` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's3',
`s4` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's4',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
我们采用不可变长度的 char 来进行测试,根据 MySQL 8.0 关于 CHAR 和 VARCHAR 类型的官方文档²,当我们只保存s1这种 ASCII 字符时,一行数据的长度很容易就可以计算出来:4 + 255 + 255 + 255 + 255 = 1024 字节
ibd 结构探测工具
我们采用阿里巴巴开源的MySQL InnoDB Java Reader³来窥探 ibd 内部所有页的情况,主要是看他们的层级。
开始插入数据
在只插入了一行数据时,窥探结果如下:
=====page number, page type, other info=====
0,FILE_SPACE_HEADER,space=1289,numPagesUsed=5,size=7,xdes.size=1
1,IBUF_BITMAP
2,INODE,inode.size=4
3,SDI
4,INDEX,root.page=true,index.id=4605,level=0,numOfRecs=1,num.dir.slot=2,garbage.space=0
5,ALLOCATED
6,ALLOCATED
此时index_tree.ibd文件的尺寸为 112KB。
1. 首次索引分级
我们继续插入数据,在插入了第 15 行后,这个 idb 文件从 1 页分裂成了 3 页:
=====page number, page type, other info=====
0,FILE_SPACE_HEADER,space=1289,numPagesUsed=7,size=8,xdes.size=1
1,IBUF_BITMAP
2,INODE,inode.size=4
3,SDI
4,INDEX,root.page=true,index.id=4605,level=1,numOfRecs=2,num.dir.slot=2,garbage.space=0
5,INDEX,index.id=4605,level=0,numOfRecs=7,num.dir.slot=3,garbage.space=7350
6,INDEX,index.id=4605,level=0,numOfRecs=8,num.dir.slot=3,garbage.space=0
7,ALLOCATED
我们能够看出,本来这 14 条数据都是在初始的那个 4 号页内部储存的,即数据部分至少有1024*14=14KB的容量,在插入第 15 条数据迈向 15KB 的时候,innodb 发了页的分级:B+ 树分出了两级,顶部为一个索引页 4,底部为两个数据页 5 和 6,5 号页拥有 7 行数据,6 号页拥有 8 行数据。这说明每一页可用的数据容量为14kB - 15KB之间。
而且,从garbage.space可以看出,5 号页是之前那个唯一的 4 号页,而新的 4 号页和 6 号页则是本次分级的时候新建的。
下面让我们继续插入数据,看它什么时候能从二层增长为三层。
2. 二层转换为三层
我以 500 为步长批量插入数据,在 16500 行的时候,还是二层:
=====page number, page type, other info=====
0,FILE_SPACE_HEADER,space=1292,numPagesUsed=37,size=1664,xdes.size=22
1,IBUF_BITMAP
2,INODE,inode.size=4
3,SDI
4,INDEX,root.page=true,index.id=4608,level=1,numOfRecs=1180,num.dir.slot=296,garbage.space=0
5,INDEX,index.id=4608,level=0,numOfRecs=7,num.dir.slot=3,garbage.space=7350
6,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
7,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
8,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
9,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0但是当表长度来到 17000 的时候,已经是三层了:
=====page number, page type, other info=====
0,FILE_SPACE_HEADER,space=1292,numPagesUsed=39,size=1728,xdes.size=22
1,IBUF_BITMAP
2,INODE,inode.size=4
3,SDI
4,INDEX,root.page=true,index.id=4608,level=2,numOfRecs=2,num.dir.slot=2,garbage.space=0
5,INDEX,index.id=4608,level=0,numOfRecs=7,num.dir.slot=3,garbage.space=7350
6,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
7,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
... ...
36,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
37,INDEX,index.id=4608,level=1,numOfRecs=601,num.dir.slot=152,garbage.space=7826
38,INDEX,index.id=4608,level=1,numOfRecs=614,num.dir.slot=154,garbage.space=0
39,ALLOCATED
40,ALLOCATED
... ...
此时,index_tree.ibd文件的尺寸为 27MB。
在整颗 B+ 树从二层转换为三层的过程中,只修改了三个页:
-
将目前唯一的索引页 4 号的数据复制到 37 号页中,level 保持不变(此时 37-63 号已经被提前
ALLOCATED出来用作备用页了) - 将 38 号页初始化成一个新的 level=1 的索引页,并将左侧 37 号页右边一半的页指针转移给 38 号页,再删除 37 号页中的原指针
- 重新初始化 4 号页,设置为顶层(level=2)索引页,创建两个页指针:第一个指向 37,第二个指向 38
为什么是 17000 行呢?我们来计算一下二层索引的极限容量:
- 已知一个最底层(level=0)的数据节点可以存储 14 条数据
-
假设索引页内部的一个页指针的长度是
4+8=12字节,那 2 层索引的极限就是:(14 1024 / 12) 14 = 16725.33
和实测值完美契合!
此时计算可知,一个索引页至少可以存储14 * 1024 / 12=1194.66666666个页指针。
3. 三层转换为四层
继续向 index_tree 表中批量插入数据,在数据继续分层之前,整棵树的结构保持不变,只是会不断增加 level=0 和 level=1 的页的数量。
但当行数来到了 21427000 行时,索引就从 3 层转换为了 4 层了,此时磁盘 ibd 文件为 24GB,探测结果如下:
=====page number, page type, other info=====
0,FILE_SPACE_HEADER,space=1292,numPagesUsed=4,size=1548032,xdes.size=256
1,IBUF_BITMAP
2,INODE,inode.size=4
3,SDI
4,INDEX,root.page=true,index.id=4608,level=3,numOfRecs=2,num.dir.slot=2,garbage.space=0
5,INDEX,index.id=4608,level=0,numOfRecs=7,num.dir.slot=3,garbage.space=7350
6,INDEX,index.id=4608,level=0,numOfRecs=14,num.dir.slot=4,garbage.space=0
... ...
1424021,INDEX,index.id=4608,level=2,numOfRecs=601,num.dir.slot=152,garbage.space=7826
1424022,INDEX,index.id=4608,level=2,numOfRecs=672,num.dir.slot=169,garbage.space=0
... ...由此可知,索引结构是这样的:
- 1 个 4 层(level=3)索引页,含有 2 个 3 层索引页的指针
- 2 个 3 层(level=2)索引页,其中左侧的 1424021 号页有 601 个底层数据页的指针,右侧的 1424022 号页有 672 个底层数据页的指针
-
601+672=1273个 2 层索引页,每页含有 1194+ 个底层数据页的指针 -
21427000/14=1530500个底层数据页,每页含有 14 条数据
转换的过程中,哪些页需要更新数据呢?还是只需要修改三个页:
- 需要将 4 号页(旧顶层页)的数据拷贝到 1424021 号页(新 level=2 左)中
-
新生成 1424022 号页(新 level=2 右),将 1424021 号页(新 level=2 左)内部右侧的 672 个页指针(
id|页号)复制到 1424022 号页中,并删除 1424021 号页中的原指针 - 重新初始化 4 号页,创建两个页指针:第一个指向 1424021,第二个指向 1424022
再增加一层需要再插入 1200 倍的数据,我们就不测试了,28TB 的磁盘阵列我也没有╮(╯▽╰)╭
计算页指针id|页号的大小
无论是中文技术文章还是英文技术文章,我甚至还查了 MySQL 8.0 InnoDB 的官方文档,并没有说“页号”的大小,甚至对于id的大小都没有一个统一的说法。下面我们尝试自己算出来:
-
在 14-15 之间一层索引转换成了二层索引,所以页可用容量最大值
1024 * 15 = 15360 -
最小值
1024 * 14 = 14336 -
在 16500-17000 之间二层索引转换成了三层索引,对应的索引数最大值为
17000 / 14 = 1214.28 -
索引数最小值为
16500 / 14 = 1178.57
我们拿最大值除以最小值,得到 15360 / 1178.57 = 13.03字节,拿最小值除以最大值,得到 14336 / 1214.28 = 11.81字节,所以我们可以得出结论:
单个
id|页号的大小应该为 12 字节或者 13 字节
接下来怎么确定呢?再拿 bigint 做一遍测试就行了。
使用 bigint 确定页号的大小
我们建立一个名叫index_tree_bigint的表:
CREATE TABLE `index_tree_bigint` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`s1` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's1',
`s2` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's2',
`s3` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's3',
`s4` char(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 's4',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;单行数据的容量从 1024 上升到了 1028。
按照同样的流程进行测试,可以发现还是 14 到 15 条的时候发生的一层转换到两层,从 12500 到 13000 条时从二层转换到了三层,我们使用同样的方法进行计算:
-
1028 * 15 / ( 12500 / 14 ) = 17.27 -
1028 * 14 / ( 13000 / 14 ) = 15.50
主键采用 bigint 类型时,单个id|页号的大小应该为 16 字节或者 17 字节。
得出结论:“页号”为 8 字节
由于页号采用奇数长度的概率非常低,我们可以得出一个十分可信的结论:在 MySQL 8 中,id 的长度和类型有关:int为 4 字节,bigint为 8 字节,“页号”的长度为 8 字节。则单个id|页号的大小应该为 12 字节或者 16 字节。
解答“2000W 行分表”问题
真实世界数据长度以及它的 4 层极限
看了一眼我司生产数据库,电商业务的常用大表“订单商品表”,实际单行数据长度为0.9KB,和我们做测试的 1KB 差别不大,所以上面的测试结果还是很符合现实世界的真实情况的。
我们取如下几个值来计算 3 层到 4 层的理论极限:
- 单页可用数据容量 14KB
-
单行数据 0.9KB,所以每页最多可以存储
14/0.9=15.5555,取整为 15 行数据 -
主键类型采用
int,页指针长度为 12 字节,所以每页最多可以存储14*1024/12=1194.6666,取整为 1194 个页指针
则三层 B+ 树的理论极限为:1194^2 * 15 = 21384540,大约 2100 万行,还是蛮符合 2000W 行分表的传说的。
四层到五层呢?
而如果需要五层,则行数需要达到 1194^3 * 15 = 25533140760,即 255 亿行,这个数字已经超过了 unsigned int 的上限 42 亿多,需要用 bigint 来做主键了,感兴趣的可以自行计算 bigint 下五层索引甚至是六层七层八层的行数极限,我在此不再赘述。
2100w 行以后,真的会发生性能极速劣化吗?并不会!
三层索引和四层索引的性能并没有什么不同,2000W 行分表已经过时了!
其实,每一次 B+ 树增高,都只会增加两个索引页,修改一个索引页,加起来只修改了三个 16KB 的数据页,无论是磁盘 IO 还是 Buffer Pool 缓存失效,对性能的影响都微乎其微:
索引从三层转换到四层,只增加了一次 IO,绝对性能降低幅度的理论极限只有1/3,而且在有 Buffer Pool 存在的情况下,性能差异微乎其微,只增加了1~2次比大小的计算成本。
那是否意味着不需要再分表了呢?
虽然三层索引和四层索引看起来性能差异不大,但是如果你的单行数据比较大,例如达到了 5KB,还是建议做一下横向分表的,这才是效果最立竿见影的减少磁盘 IO 次数的优化方法:
- 单行数据为 0.9KB 时,三层树的极限行数是 2100 万,但是如果单行数据来到 5KB,那这个极限会变成 285 万行,这可能就不太够了
- 数据页拥有局部性:每次从磁盘读取都是一整页的数据,所以读取某一行数据以后,它 id 附近的数据行也已经在内存缓存里了,读取性能十分优异
- 在连续读取多行时(例如全表条件查询),巨大的单行数据将在让“局部性”优势迅速丧失的同时,会引发磁盘 IO 次数出现数量级规模的上升,这就是单行数据比较大的表读取起来感觉格外慢的原因
到底该何时分表?
2017 年发布的阿里巴巴 Java 开发手册中写道“单表行数超过 500 万行或者单表容量超过 2 GB ,才推荐进行分库分表”,被很多技术博文写成了:阿里巴巴推荐超过 500 万行的表进行分表,这种理解是错误的。
虽然经过我的实测,在每行数据定长 1024 字节,Buffer Pool 配置为 22GB,在单表体积 24GB 的情况下,四层索引和三层索引并没有任何性能差异,但是现实世界中的数据表可不是这么严丝合缝:
- 为了节约空间和保持扩展性,绝大多数短字符串类型采用的是 varchar 而非定长的 char,这就让 level=0 的每一页包含的数据行数不一致,这会让这颗“平衡多路查找树”不怎么平衡
- 生产表经常面临数据删除和更新:同层的页之间的双向链表和不同层页之间的单向指针都需要经常变化,同样会让这棵树变的不平衡
- 一张表使用的越久,ibd 文件中的碎片就越多,极端情况下(例如新增 10 行删除 9 行)会让数据页的缓存几乎失效
-
磁盘上单文件体积过大,不仅在读取 IOPS 上不如多文件,还会引发文件系统的高负载:单个文件描述符也是一种
单点,大文件的读写性能都不太行,还容易浪费大量内存
那么,该如何回答“到底该何时分表”这个问题呢?很遗憾并没有一个放之四海皆准的答案,这和每个表的读取、新增、更新的具体情况是分不开的。
虽然在数据库技术层面我们无法给出何时分表的答案,但是从软件工程层面我们可以得出一个结论:
能不分就不分,不到万不得已不搞分表,如果能靠加索引或者加内存来解决就不要考虑分表,分表会对业务代码造成根本性的影响,会产生长久的技术债务。
B+ 树和分表的问题我们就讨论到这里,下面我们简单分析一下 Buffer Pool 的设计思想和运行规律。
内存缓存 Buffer Pool
Buffer Pool 是在 MySQL 启动的时候,向操作系统申请的一片连续的内存空间,默认为 128MB,强烈建议任何一台 MySQL 服务器都根据自己的机器资源情况,增大配置的内存值,这玩意儿能把 MySQL 的性能提升多个数量级。
缓存池的大小
缓存池的大小由innodb_buffer_pool_size参数来管理,一般建议大家设置成系统可用内存的 75%,但是根据我的经验,对于普通的“冷热均衡”的数据库这样是合理的,因为热数据较少,但是如果你需要在短时间内(如几天)普遍地读写几乎所有表的所有数据,那这个比例最好设置在 50% 附近,否则在运行一段时间后将会爆内存(OOM 错误),MySQL 进程会被杀掉。
缓存池的基本结构
缓存池和磁盘数据一样,分为一个又一个 16KB 的页来进行管理。除了缓存“索引页”和“数据页”,缓存池里面还有 undo 页,插入缓存、自适应哈希索引、锁信息等。
虽然缓存池已经在内存中了,但是既然缓存池是一组 16KB 的页,那它就需要一个额外的内存索引来保存每一页的表空间、页号、缓存页地址、链表节点信息,这个结构叫控制块。N 个控制块和 N 个 16KB 数据页连在一起就是 Buffer Pool 占据那一段连续内存。
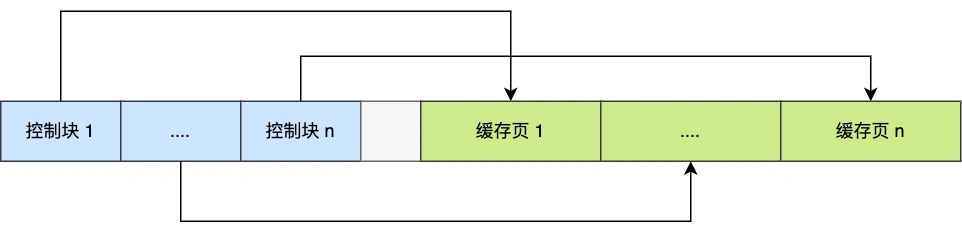
引入缓存池后,数据如何读写
缓存池中的 16KB 页是和磁盘上的页一一对应的,这就带来了读写两个方向的改变:
- 读数据时,如果该页已经在内存中了,则无需再浪费一次磁盘 IO。
- 写数据时,会直接将数据写入缓存中的页(不影响之后的读取),并在成功写入 redo log 之后返回成功。同时会将该页设置为脏页,等待后台进程将数据真正写入磁盘。
缓存池 LRU 算法
除了控制块和数据页,Buffer Pool 中还存在着管理空闲页的free 链表和管理脏页的flush 链表,我们不再深入了解。
但是,管理缓存生命周期的 LRU 算法我们不能放过,必须狠狠地了解它一下:
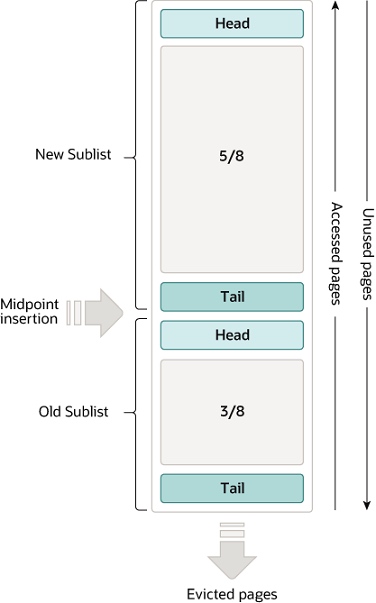
传统的 LRU 算法只用一个链表就实现了“移动至头部”和“淘汰尾部”两个操作,什么 InnoDB 非要搞一个变体呢?还是因为 B+ 树:由于底层数据的非连续性,导致 Buffer Pool 会遇到两个比较严重的问题:预读失效和缓冲池污染。
预读失效
预读失效很容易理解,因为预读本质上是基于局部性对需求的一种预估,正常的 SQL 并不能保证每一条取出的数据都是大概集中的,例如取性别为女的用户,就需要跳着走完全表,预读失效非常正常。
LRU 链表将数据分为新生代和老生代两个区域,分别占据5/8和3/8的内存空间,预读时只插入老生代的头部,同时老生代尾部元素会被淘汰。当数据真的被读取时,这一页会被立刻转移到新生代的头部,并且会挤出去一个新生代尾部的元素进入老生代的头部,数据还在缓存中。
不知道大家发现了没有,这的操作的本质是给 LRU 算法加了一层 LRU 算法,减小了缓存粒度。
缓冲池污染
这个问题是非常符合本文主旨的一个问题:由于磁盘数据库拥有极大的体量,相比之下内存容量却十分捉襟见肘,所以在用内存来做磁盘缓存时,一旦需求不满足局部性,缓存会被迅速劣化:当一条 SQL 需要扫描海量的数据页时,其它表用得好好的热数据嘎的一下就被清出内存了,结果就是磁盘 IO 数量突然增加,系统崩溃。
于是 InnoDB 给“数据被读取时,这一页会从老生代转移到新生代的头部”这个操作加了个条件:在老生代里面待的时间要足够久。
这里面有两个点非常巧妙:
- 改变的是“转移页操作”所需要的条件,而且这个条件(即留存时间)的判断非常简单,只需要在加入老生代的时候增加一个时间戳就行,4 个字节,除此之外无需任何维护
- 采用时间而不是次数来做限制,更加符合数据库的最终用户——人的真实需求。读取次数可能因为技术原因而增加,时间不会。没有无缘无故的爱,更没有无缘无故的读取。
Buffer Pool 应该怎么优化
- 内存配置的越大越好:多一倍的内存,比多一倍的 CPU 更能提高数据库性能
- 减少对冷数据的随机调用:优化定时任务和队列的业务代码,避免这种情况
- 在大批量执行小修改的时候、尽量自己控制事务:由于 InnoDB 底层的数据隔离机制,让它的每一个写动作都是一个事务,所以如果你要在一次会话中写多行数据,最好自己控制事务,可以显著减少对缓冲池的影响以及磁盘 IO 数量
- 避免修改主键:修改主键的值会带来大量的数据移动,磁盘会不堪重负,缓存会疯狂失效
接下来
一万多字的 InnoDB 详解文章终于完成了,下一篇文章我们将在本文的基础上,细数四代分布式数据库的变迁:NewSQL、计算存储分离、Paxos、Shared-Nothing、列存储,并且详细分析国产数据库双雄 TiDB 和 OceanBase 的技术架构,看看市面上可用的这些分布式数据库,到底能不能支撑得住 500 万 QPS。
参考资料
- mysql 最大建议行数 2000w, 靠谱吗? https://my.oschina.net/u/4090830/blog/5559454
- The CHAR and VARCHAR Types https://dev.mysql.com/doc/refman/8.0/en/char.html
- MySQL InnoDB Java Reader https://github.com/alibaba/innodb-java-reader


评论:

2023-09-27 10:36
这篇文章也有说明